Wordle
Écrire un solveur du jeu Wordle qui propose un premier mot puis qui propose le mot suivant en fonction du motif coloré qu’on lui transmet en réponse au premier mot rentré, et ainsi de suite jusqu’à ce qu’il nous propose le mot du jour. Et le tout en moins de 6 essais.
Pour récupérer dans le code la liste des 2315 mots pouvant être solution :
import pandas as pd
url1 = 'https://gist.githubusercontent.com/cfreshman/a03ef2cba789d8cf00c08f767e0fad7b/raw/5d752e5f0702da315298a6bb5a771586d6ff445c/wordle-answers-alphabetical.txt'
liste_solutions = pd.read_csv(url1,header=None)
liste_solutions = liste_solutions[0].values.tolist()
Et pour la liste des mots 10657 mots autorisés (ne comprenant pas les mots solutions) :
url2 = 'https://gist.githubusercontent.com/cfreshman/cdcdf777450c5b5301e439061d29694c/raw/de1df631b45492e0974f7affe266ec36fed736eb/wordle-allowed-guesses.txt'
liste_mots = pd.read_csv(url2,header=None)
liste_mots = liste_mots[0].values.tolist()
Mission supplémentaire : évaluer la qualité du solveur
Pour cela, il faut tester le programme sur chacun des 2315 mots pouvant être solution en laissant le programme jouer tout seul et en vérifiant qu’il obtient le mot en au plus 6 essais.
- Donner le pourcentage de réussite.
- Donner le nombre d’essais moyen pour trouver la solution.
Aide
La démarche la plus efficace utilise la notion d’entropie de l’information :
- Vidéo de Davide Louapre
- Explications supplémentaires de David Louapre.
Une solution possible
Disclaimer : cette solution n’est pas obtimale puisqu’elle n’utilise que les mots solutions (pour aller plus vite) ce qui nous prive d’un fort potentiel supplémentaire de discrimination.
Remarquons aussi qu’une stratégie reposant sur la liste complète de mots sans connaître par avance l’ensemble des mots solutions (solution “sans triche” donc) ne serait pas forcément plus efficace (meilleure discrimination mais pour un choix bien plus grand). On va le tester à la fin.
Import des modules et définition des fonctions dont on aura besoin :
import numpy as np
import pandas as pd
import csv
import json
def obtenir_motif(mot: str,solution: str) -> str:
"""
donne le motif coloré de la tentative "mot" pour un mot à trouvé valant "solution"
exemple : si solution = "aroma" et mot = "raise", alors la fonction retourne le motif "JJGGG"
"""
motif_l = [0]*5
sol = list(solution)
indices = list(range(5))
for i in indices[:]:
if mot[i] == solution[i]:
motif_l[i]='V'
sol.remove(mot[i])
indices.remove(i)
for i in indices:
if mot[i] in sol:
motif_l[i] = 'J'
sol.remove(mot[i])
else:
motif_l[i] = 'G'
motif = ''
for s in motif_l:
motif += s
return motif
def conv_motif_nb(motif: str) -> int:
"""
considère le motif coloré constitué de 5 lettres valant 'G', 'J' ou 'V' comme un nombre écrit en base 3
avec 'G' = 0, 'J' = 1, et 'V' = 2
la fonction retourne l'entier correspondant
"""
nb = 0
rg = 0
for c in motif[::-1]:
for i in range(3):
if c=='GJV'[i]:
nb += i*3**rg
rg += 1
return nb
def entropie(mot_test: str,liste_mots: list) -> tuple:
"""
la liste en argument est la liste des mots restant possibles
pour chaque motif possible, on crée une liste des mots donnant ce motif lorsqu'il est comparé au mot_test
on calcul alors l'entropie de mot_test sur la distribution de ses motifs
la fonction retourne à la fois l'entropie calculée et la liste liste_mots_par_motifs qui contient la liste des mots correspondant à chacun des motifs
"""
n = len(liste_mots)
liste_mots_par_motifs = [[] for _ in range(3**5)]
for mot in liste_mots:
liste_mots_par_motifs[conv_motif_nb(obtenir_motif(mot_test,mot))]+=[mot]
res = 0
for L in liste_mots_par_motifs:
X = len(L)
if X:
res += -X/n*np.log2(X/n)
return res,liste_mots_par_motifs
def entropie_depart(mot_test: str,liste_mots_depart: list) -> tuple:
n = len(liste_mots_depart)
liste_mots_par_motifs = [[] for _ in range(3**5)]
for i in range(n) :
liste_mots_par_motifs[conv_motif_nb(obtenir_motif(mot_test,liste_mots_depart[i]))]+=[i]
res = 0
for L in liste_mots_par_motifs :
X = len(L)
if X != 0 :
res += -X/n*np.log2(X/n)
return res,liste_mots_par_motifs
def resultats_depart(liste_depart: list) -> list:
Resultats = []
for i in range(len(liste_depart)):
s,liste_indices_mots_par_motifs = entropie_depart(liste_depart[i],liste_depart)
Resultats.append((s,i,liste_indices_mots_par_motifs))
return Resultats
def resultats(liste_depart: list,liste_mots_restants: list) -> list:
Resultats = []
for mot in liste_depart:
s,liste_mots_par_motifs = entropie(mot,liste_mots_restants)
Resultats.append((s,mot,liste_mots_par_motifs))
return Resultats
Le code suivant permet d’enregistrer la liste donnée par la fonction resultats_depart dans un fichier csv pour s’éviter de refaire ce premier long calcul à chaque fois qu’on lance le programme. Le fichier csv produit pèse 31,5 Mo (et plus d'1 Go avec tous les mots possibles…).
# Liste des mots solutions
url = 'https://gist.githubusercontent.com/cfreshman/a03ef2cba789d8cf00c08f767e0fad7b/raw/5d752e5f0702da315298a6bb5a771586d6ff445c/wordle-answers-alphabetical.txt'
dataf = pd.read_csv(url,header=None)
liste_mots_dep = dataf[0].values.tolist()
Resultats = resultats_depart(liste_mots_dep[:])
with open('liste_base.csv','w') as f:
write = csv.writer(f)
write.writerows(Resultats)
Maintenant, on peut jouer…
Demandons déjà quelles sont, d’après notre modèle, les 3 meilleures et les 3 pires ouvertures :
Rescla = sorted(Resultats,reverse=True)
for i in range(3):
print(Rescla[i][1].upper())
print('-'*5)
for i in range(1,4):
print(Rescla[-i][1].upper())
RAISE
SLATE
CRATE
-----
FUZZY
JAZZY
MAMMA
En utilisant la liste complète des mots, on aurait obtenu :
TARES
LARES
RALES
-----
QAJAQ
XYLYL
IMMIX
Écrivons maintenant le code nous permettant de vaincre le Wordle du jour :
# on récupère les résultats du fichier csv
dataf_result = pd.read_csv('liste_base.csv',header=None)
liste_resultats = dataf_result.values.tolist()
Resultats = []
for L1 in liste_resultats:
L = []
a,b,c = L1
k = 0
c = json.loads(c)
for L2 in list(c):
L.append([])
for i in L2:
L[k].append(liste_mots_dep[int(i)])
k += 1
Resultats.append((float(a),liste_mots_dep[int(b)],L))
# Et on récupère aussi la liste des mots solutions
url = 'https://gist.githubusercontent.com/cfreshman/a03ef2cba789d8cf00c08f767e0fad7b/raw/5d752e5f0702da315298a6bb5a771586d6ff445c/wordle-answers-alphabetical.txt'
dataf = pd.read_csv(url,header=None)
liste_mots_dep = dataf[0].values.tolist()
# puis on lance la machine
essais = 1
essai1 = max(Resultats)[1].upper()
print("\n")
print(f"Tentez le mot '{essai1}'")
print()
motif_obtenu = input("puis entrez le motif obtenu\nsous la forme d'un mot de 5 lettres\nchoisies parmi 'g', 'j' et 'v' où\n'g' désigne une lettre grise,\n'j' une lettre jaune et\n'v' une lettre verte\n\nmotif : ").upper()
while True or essais <= 5:
liste_mots = max(Resultats)[2][conv_motif_nb(motif_obtenu)]
if len(liste_mots) == 1:
print("\n"+" "*4+"-"*9)
print('-->',end = ' ')
print(f"| {liste_mots[0].upper()} |")
print(" "*4+"-"*9+"\n")
break
Resultats = resultats(liste_mots_dep,liste_mots)
nvessai = max(Resultats)[1].upper()
print()
print(f"Tentez le mot '{nvessai}'")
print()
motif_obtenu = input("motif : ").upper()
essais += 1
Exemple :
puis entrez le motif obtenu
sous la forme d'un mot de 5 lettres
choisies parmi 'g', 'j' et 'v' où
'g' désigne une lettre grise,
'j' une lettre jaune et
'v' une lettre verte
motif : gjvgg
Tentez le mot 'CLOWN'
motif : ggjgg
---------
--> | AXIOM |
---------
Pour tester tous les mots et ainsi évaluer la stratégie :
url = 'https://gist.githubusercontent.com/cfreshman/a03ef2cba789d8cf00c08f767e0fad7b/raw/5d752e5f0702da315298a6bb5a771586d6ff445c/wordle-answers-alphabetical.txt'
liste = pd.read_csv(url,header=None)
liste = liste[0].values.tolist()
succes = 0
Distrib = [0]*6
nb_moy_tent = 0
count = 0
print("Patience... Le premier calcul est un peu long\n")
Res = resultats(liste[:],liste[:])[:]
for mot_mystere in liste:
essais = 1
conv_motif_nb
Resultats = Res[:]
motif_obtenu = obtenir_motif('raise',mot_mystere)
if mot_mystere == 'raise':
succes += 1
Distrib[0] += 1
nb_moy_tent += essais
print(count,mot_mystere,essais)
count += 1
continue
while essais <= 6:
liste_mots = max(Resultats)[2][conv_motif_nb(motif_obtenu)]
Resultats = resultats(liste,liste_mots)
motif_obtenu = obtenir_motif(max(Resultats)[1],mot_mystere)
essais += 1
if motif_obtenu == "VVVVV":
succes += 1
Distrib[essais-1] += 1
nb_moy_tent += essais
print(count,mot_mystere,essais)
break
if len(liste_mots) == 1:
succes += 1
Distrib[essais-1] += 1
nb_moy_tent += essais
print(count,mot_mystere,essais)
break
count += 1
print(f"Nombre de mots testés : {count}")
print(f"Nombre de mots trouvés en 6 tentatives ou moins : {succes}")
Moy = 0
for i in range(6):
print(f"Nombre de mots trouvés en {i+1} essais : {Distrib[i]}")
Moy += (i+1)*Distrib[i]
Moy /= succes
print(f"Le mot a en moyenne été trouvé en {Moy:.2f} essais")
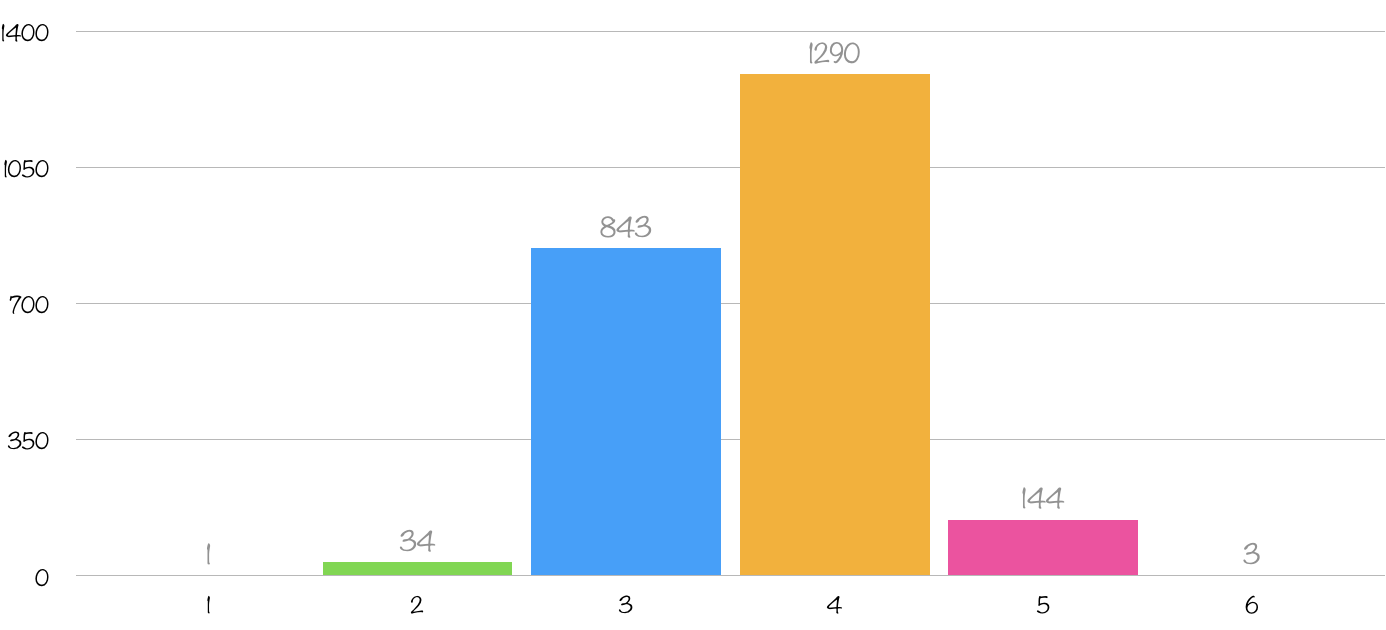
Nombre de mots testés : 2315
Nombre de mots trouvés en 6 tentatives ou moins : 2315
Nombre de mots trouvés en 1 essais : 1
Nombre de mots trouvés en 2 essais : 34
Nombre de mots trouvés en 3 essais : 843
Nombre de mots trouvés en 4 essais : 1290
Nombre de mots trouvés en 5 essais : 144
Nombre de mots trouvés en 6 essais : 3
Le mot a en moyenne été trouvé en 3.67 essais
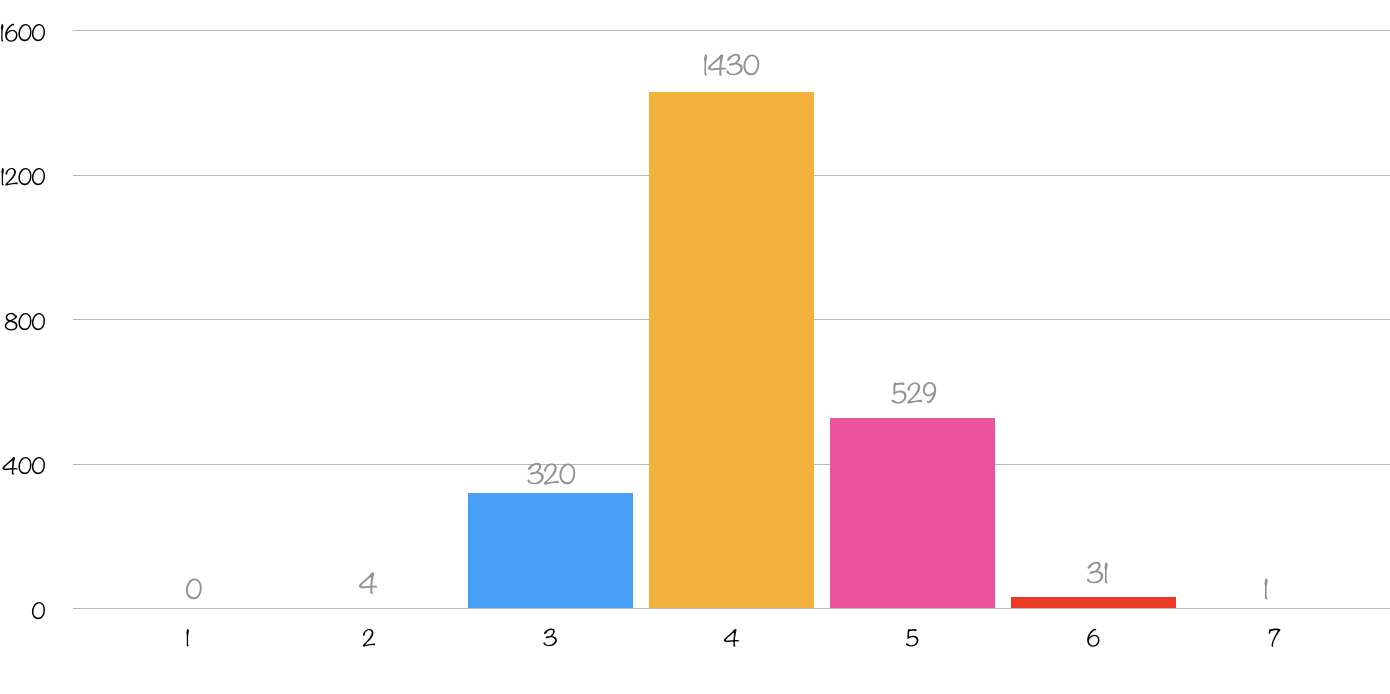
En utilisant tous les mots autorisés mais sans isoler le sous-ensemble solution (sans “triche”), les résultats sont moins bons : un mot n’est pas découvert (il faut 7 essais pour découvrir FERRY) et la moyenne est au-delà de 4 essais.
Nombre de mots testés : 2315
Nombre de mots trouvés en 6 tentatives ou moins : 2314
Nombre de mots trouvés en 1 essais : 0
Nombre de mots trouvés en 2 essais : 4
Nombre de mots trouvés en 3 essais : 320
Nombre de mots trouvés en 4 essais : 1430
Nombre de mots trouvés en 5 essais : 529
Nombre de mots trouvés en 6 essais : 31
Le mot a en moyenne été trouvé en 4.11 essais