Types structurés
Les types structurés (chaînes, tuiles, listes, dictionnaires, ensembles) sont des objets composés ; ils contiennent eux-mêmes d’autres objets.
Certains de ces objets composites sont en plus indicés. Comme leur nom l’indique, on peut parcourir les éléments présents d’une structure indicée à l’aide d’un indice (un nombre entier étiquetant l’indice). Les structures indicés sont donc ordonnées, ce sont des séquences.
L’indice commence toujours à 0.
Et donc si la structure contient n éléments, le dernier indice est n-1.
Structures indicées immuables (chaînes, tuples)
Une structure est dite immuable si on ne peut pas modifier les éléments qu’elle contient une fois qu’elle est construite.
Il y a deux structures de ce type en Python : les chaînes de caractères (type string) et les tuples (type tuple).
- Les chaînes de caractères sont des séquences de caractères (du texte) définies par des apostrophes
', des guillemets", des triples apostrophes'''ou des triples guillemets"""('abc',"abc",'''abc''',"""abc""").
Les chaînes de caractères peuvent être constituées de tous les caractères possibles, y compris des emojis 👍.
Les guillemets "" permettent d’utiliser des apostrophes ' dans la chaîne sans que cela ne la ferme ("C'est bon").
Les triples apostrophes ''' ou guillemets """ permettent d’écrire des chaînes sur plusieurs lignes (on utilise de telles chaînes pour les signatures des fonctions).
L’espace est un caractère comme un autre !
- Les tuples sont des ensembles d’objets (pas forcément du même type) placés entre parenthèses (pas obligatoires) et séparés par des virgules comme
(3.2, 'abc', True).
len
La fonction native len() permet d’obtenir le nombre d’éléments présents dans la structure, c’est-à-dire sa longueur (len est l’‘abréviation de length).
len('abc')
3
len((3.2, 'abc', True))
3
Même si le deuxième élément du tuple du dernier exemple est lui-même composé, len le considère comme un (et un seul) des éléments du tuple.
De même, si un tuple contient un autre tuple imbriqué, il ne comptera que pour un seul élément pour len :
len(('a','b',(1,2,3),18))
4
Accès par indice d’un élément
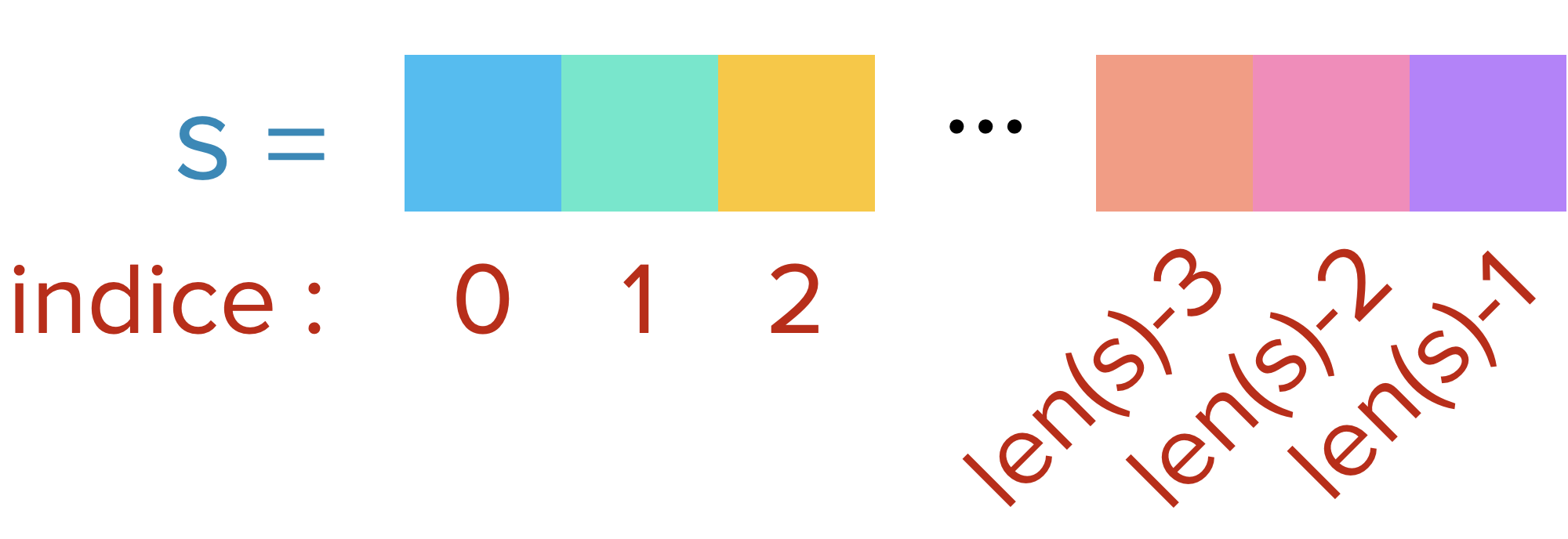 On place l’indice de l’élément qui nous intéresse entre crochets pour le récupérer :
On place l’indice de l’élément qui nous intéresse entre crochets pour le récupérer :
S = 'abcdefghijklmnopqrstuvwxyz'
n = len(S)
print('de',S[0],'à',S[n-1])
de a à z
s[n] provoque l’erreur classique IndexError: string index out of range.
Si $n$ est le nombre d’éléments de la structure (donné par len), alors l’indice doit être un entier inférieur ou égal à $n-1$.
Si une structure indicée se trouve enchassée au sein d’une autre structure indicée, on peut aussi accéder à ses éléments :
T = (1,'abcd',2)
len(T[1])
4
T[1][3]
d
Autre source d’erreur : on ne peut pas modifier la valeur d’un élément dans une structure immuable.
T = (1,2,3)
T[2] = 4
TypeError: 'tuple' object does not support item assignment
'abc'[1] = 'd'
TypeError: 'str' object does not support item assignment
Concaténation +
L’opérateur + permet de concaténer deux structures du même type.
'abc'+'de'
'abcde'
(1,'b',2.2) + (True,1/5)
(1, 'b', 2.2, True, 0.2)
La longueur de la structure résultante vaut la somme des longueurs des deux tructures concaténées.
Répétition *
L’opérateur * permet de répéter une structure.
'abc'*2
abcabc
On peut combiner * et + :
('z'*5 + ' ')*3
zzzzz zzzzz zzzzz
Tranches
On peut extraire plusieurs éléments d’une structure indicée en une seule fois grâce au découpage en tranches (slicing en anglais). On utilise les crochets comme pour l’indexation mais on utilise maintenant 2 ou 3 indices séparés par :.
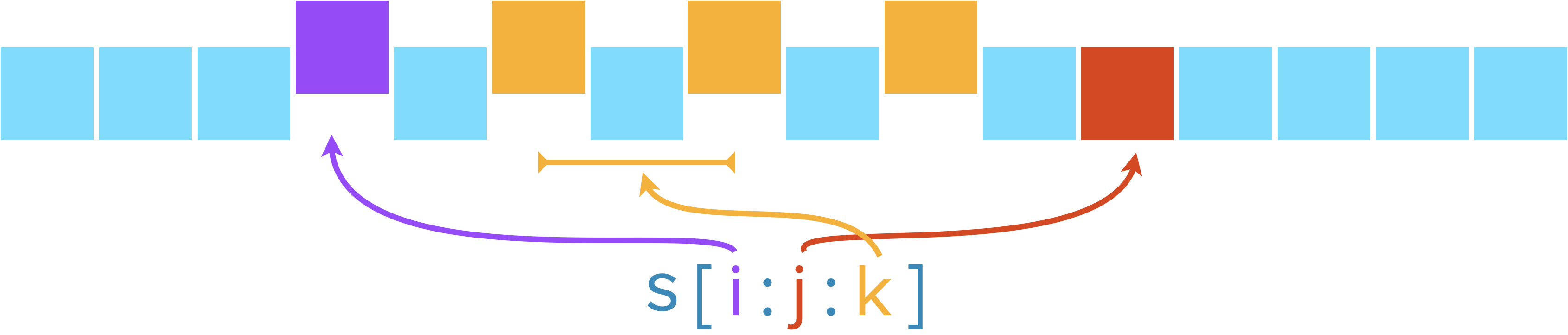
La tranche va du premier indice (inclu) jusqu’au deuxième indice (exclu).
S = '0123456789'
S[1:4]
'123'
Cette règle d’exclusion du deuxième indice permet d’avoir une épaisseur de tranche (len(S[i:j])) valant la différence entre les deux indices (j-i).
Si on omet le premier indice ([:j]), on part du début. Si on omet le second ([i:]), on va jusqu’au bout.
S[:4],S[5:]
('0123', '56789')
Un troisième indice installe un pas dans la découpe :
S[::2],S[1::4]
('02468', '159')
Et si le troisième indice est négatif, il permet de parcourir la séquence en sens inverse :
S[::-1],S[8:0:-2]
('9876543210', '8642')
Appartenance in
On peut tester l’appartenance d’un élément ou d’une tranche à une structure composée grâce au mot clé in :
'b' in (5,'a',12.5)
False
'567' in S
True
Listes
Une liste (type list) est une collection d’objets placés entre crochets et séparés par des virgules.
Exemple : L = [0.0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8]
Comme avec les chaînes de caractères et les tuples :
- on accède à un élément via son indice :
L[3]renvoie0.3. - on obtient le nombre d’éléments d’une liste grâce à la fonction
len:
len(L)retourne9; - on peut concaténer deux listes avec
+:
[5,6]+[7,8]donne[5,6,7,8]; - on peut extraire par tranche des éléments :
L[1:6]donne[0.1,0.2,0.3,0.4,0.5]; - on peut tester la présence d’un élément grâce au mot clé
in:
0.1 in LrenvoieTrueet1 in LrenvoieFalse.
Mais contrairement aux chaînes de caractères et aux tuples, les listes ne sont pas immuables. On peut donc réaffecter des éléments.
En reprenant la liste L précédente, si on écrit L[2] = 'a', L devient [0.0,0.1,'a',0.3,0.4,0.5,0.6,0.7,0.8].
Création d’une liste
par duplication :
L’opérateur * permet de créer une liste répétant un élément.
Par exemple, pour créer une liste L de 10 zéros, il suffit d’écrire L = [0]*10.
par append successifs :
On initialise une liste vide ([]), puis on la garnit élément par élément grâce à la méthode append.
Exemple :
L = []
for i in range(10):
L.append(i/10)
L
[0.0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8]
par compréhension
La construction par compréhension d’une liste est une méthode concise et élégante. L’idée est d’intégrer les boucles et enventuelles conditions dans une seule expression entre crochets pour aboutir à une définition plus directe de la liste.
Exemples :
L1 = [i/10 for i in range(9)]
L2 = [k**2 if (k%2==0) else k**3 for k in range(9)]
print(f"{L1 = }")
print(f"{L2 = }")
L1 = [0.0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8]
L2 = [0, 1, 4, 27, 16, 125, 36, 343, 64]
Copie d’une liste
Si on copie une liste en l’affectant à un nouveau nom, alors toute modification de l’ancienne liste se répercutera sur la nouvelle (et inversement). Les deux noms pointent en réalité vers le même espace mémoire. En effet, lorsqu’on affecte une liste à un nom de variable via =, ce n’est pas la liste mais sa référence (son adresse mémoire) qui est assignée à la variable. Et donc lorsqu’on affecte la liste à une nouvelle variable, c’est une copie de la référence et non des valeurs qui est faite.
L_originelle = ['🍓', '🍇', '🍊']
L_copie = L_originelle
L_originelle[1] = '?'
print(L_originelle,L_copie)
['🍓', '?', '🍊'] ['🍓', '?', '🍊']
Aucune différence !
Si on veut que la liste copiée conserve ses éléments tels qu’ils étaient au moment de la copie, on peut soit utiliser une “copie par tranche”, en affectant une tranche complète (avec [:]) de la liste, soit utiliser la méthode copy(), soit utiliser la fonction list.
L_originelle = ['🍓', '🍇', '🍊']
L_copie_1 = L_originelle[:]
L_copie_2 = L_originelle.copy()
L_copie_3 = list(L_originelle)
L_originelle[1] = '?'
print(L_originelle,L_copie_1,L_copie_2,L_copie_3)
['🍓', '?', '🍊'] ['🍓', '🍇', '🍊'] ['🍓', '🍇', '🍊'] ['🍓', '🍇', '🍊']
'?' ne se retrouve pas dans les copies !
Mais ces deux copies n’en restent pas moins superficielles. En effet, si la liste originelle contient des éléments mutables (comme une autre liste), alors seule l’adresse de ceux-ci est copiée, et s’ils sont modifiés, la copie aussi le sera :
L = ['🍋','🍑',['🍈','🍒'],'🍏']
L_copie = L[:]
L.append('🥥')
L[2].append('🍌')
print(L_copie)
['🍋', '🍑', ['🍈', '🍒', '🍌'], '🍏']
'🥥' ne se retrouve pas dans la copie, mais 🍌 y est bien…
Retirer un élément
La méthode pop() permet de retirer le dernier élément d’une liste.
L = ['🥥', '🍐', '🍋', '🍒']
print(f"{L.pop() = }")
print(f"{L = }")
L.pop() = '🍒'
L = ['🥥', '🍐', '🍋']
Comme on le voit, pop retourne l’élément retiré (c’est une expression), et une fois que pop a été utilisé, l’élément a disparu.
Si on veut retirer un autre élément que le dernier et qu’on connaît son indice i, on peut utiliser pop(i), mais on peut aussi utiliser le slicing (L[i:i+1]=[]) ou encore le mot clé del (del L[i]).
L1 = ['🥥', '🍐', '🍋', '🍒']
L2 = ['🥥', '🍐', '🍋', '🍒']
L3 = ['🥥', '🍐', '🍋', '🍒']
# Si on veut retirer la poire
L1.pop(1)
L2[1:2]=[]
del L3[1]
print(L1)
print(L2)
print(L3)
['🥥', '🍋', '🍒']
['🥥', '🍋', '🍒']
['🥥', '🍋', '🍒']
Et si plutôt que l’indice de l’élément à retirer, on veut utiliser sa valeur, on emploie la méthode remove.
L = ['🥥', '🍐', '🍋', '🍒']
# Si on veut retirer la poire
L.remove('🍐')
print(L)
['🥥', '🍋', '🍒']
Dictionnaires
Un dictionnaire (type dict) est une collection d’objets, comme une liste ou un tuple, mais au lieu d’indicer les objets s’y trouvant (appelés valeurs) par un nombre, on utilise une clé.
Les dictionnaires sont l’implémentation en Python des tables de hachage.
Une clé peut être n’importe quel objet immuable, mais il s’agit le plus souvent d’une chaîne de caractères.
Pour créer un dictionnaire, on utilise la syntaxe {clé1 : valeur1, clé2 : valeur2, ...}.
Exemple où les clés sont des prénoms et les valeurs, des notes :
note = {'Giselle' : 7.5, 'Alphonse' : 12, 'Dudule' : 7.5, 'Berthe' : 16.5}
Chaque valeur peut être récupérée grâce à la clé comme s’il s’agisait d’un indice : note['Dudule'] donne 7.5
Ajouter une clé à un dictionnaire
On peut ajouter une entrée au dictionnaire en écrivant simplement dico[nouvelleClé]=valeur.
note['Raoul'] = 14 # ajoute la note de Raoul au dictionnaire note
print(note)
{'Giselle': 7.5, 'Alphonse': 12, 'Dudule': 7.5, 'Berthe': 16.5, 'Raoul': 14}
On peut partir d’un dictionnaire vide {} et le construire ainsi étape par étape :
coef = {} # dictionnaire vide
coef['maths'] = 9
coef['physique'] = 10
coef['philo'] = 9
print(coef)
{'maths': 9, 'physique': 10, 'philo': 9}
Comme les listes, les dictionnaires sont des objets mutables.
note['Berthe'] = 18 # modifie la note de Berthe dans le dictionnaire note
print(note)
{'Giselle': 7.5, 'Alphonse': 12, 'Dudule': 7.5, 'Berthe': 18, 'Raoul': 14}
Chaque clé doit être unique, mais les valeurs peuvent être identiques (comme les notes de Dudule et Giselle).
Tenter d’accéder à une clé qui ne figure pas dans le dictionnaire se solde par une erreur.
print(note['Gourmandine']) # la clé Gourmandine n'existe pas
KeyError: 'Gourmandine'
Pour y échapper, on peut tester la présence d’une clé grâce à in.
Exemple : à partir d’une liste de 12 éléments pris au hasard parmi les entiers de 1 à 10, fabriquons un dictionnaire qui compte les occurrences de chacun des 10 entiers :
from random import randint
L = []
for i in range(12):
L = L+[randint(1,10)]
effectifs = {}
for e in L:
if not e in effectifs:
effectifs[e] = 1
else:
effectifs[e] = effectifs[e]+1
print(effectifs)
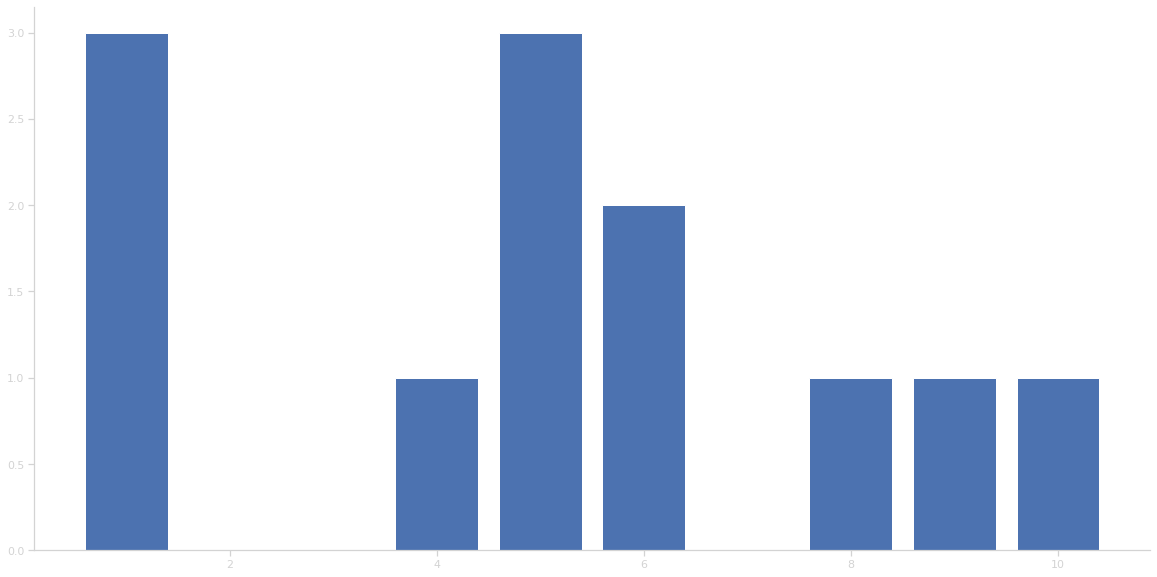
{5: 3, 10: 1, 9: 1, 4: 1, 8: 1, 6: 2, 1: 3}
Sans la condition, effectifs[e]+1 aurait levé une KeyError car le dictionnaire n’a initialement aucune entrée et donc effectifs[e] n’est pas défini.
Retirer une clé
On peut retirer une clé d’un dictionnaire grâce au mot clé del.
del note['Alphonse']
print(note)
{'Giselle': 7.5, 'Dudule': 7.5, 'Berthe': 18, 'Raoul': 14}
Si on utilise del sur une clé inexistante, une erreur KeyError est là encore produite.
Parcourir un dictionnaire
Les méthodes keys et values permettents de récupérer les clés et valeurs d’un dictionnaire sous forme d’itérables, ce qui peut s’avérer pratique pour un tracé, par exemple.
import matplotlib.pyplot as plt
clés = effectifs.keys()
valeurs = effectifs.values()
plt.bar(clés, valeurs)
plt.show()
La méthode items regroupe clés et valeurs au sein de tuples (clé,valeur).
for clé, valeur in effectifs.items():
print('nombre de',clé,':',valeur)
nombre de 5 : 3
nombre de 10 : 1
nombre de 9 : 1
nombre de 4 : 1
nombre de 8 : 1
nombre de 6 : 2
nombre de 1 : 3
Les dictionnaires sont des ensemble de paires clé-valeur qui n’ont aucun ordre particulier. Les dictionnaires ne sont donc pas des séquences.
Comme pour les listes, une affectation d’un dictionnaire existant à une nouvelle variable n’en copie que la référence. Toute modification de l’un se retrouve dans l’autre.
Et si on veut conserver invariante les valeurs copiées, on peut ici aussi utiliser la méthode copy().
infos = {'prénom': 'Russell', 'nom': 'Bell', 'alias': 'Stringer', 'notes': [13,18,7]}
infos_copie = infos.copy()
infos['prénom'] = infos.pop('alias')
infos['notes'][:] = ['abs']
print(infos)
print(infos_copie)
{'prénom': 'Stringer', 'nom': 'Bell', 'notes': ['abs']}
{'prénom': 'Russell', 'nom': 'Bell', 'alias': 'Stringer', 'notes': ['abs']}
On remarque que le remplacement du prénom par l’alias et la suppression de l’alias n’ont pas été répercutés sur la copie, par contre la modification de la liste de notes, objets mutable, oui.