Bases de données
Les bases de données (database en anglais) sont une forme d’organisation des données. Elles permettent de centraliser différentes données en évitant les duplications inutiles et en garantissant un accès contrôlé évitant les corruptions.
 Une base de données peut gérer des données organisées suivant différents modèles : navigationnel, hierarchique, relationnel, post-relationnel… C’est le modèle relationnel, le plus utilisé, qui va nous intéresser ici.
Une base de données peut gérer des données organisées suivant différents modèles : navigationnel, hierarchique, relationnel, post-relationnel… C’est le modèle relationnel, le plus utilisé, qui va nous intéresser ici.
Dans un modèle relationnel, les données sont organisées dans des tables (des tableaux à deux dimensions) ayant des relations entre elles via des clés étrangères.
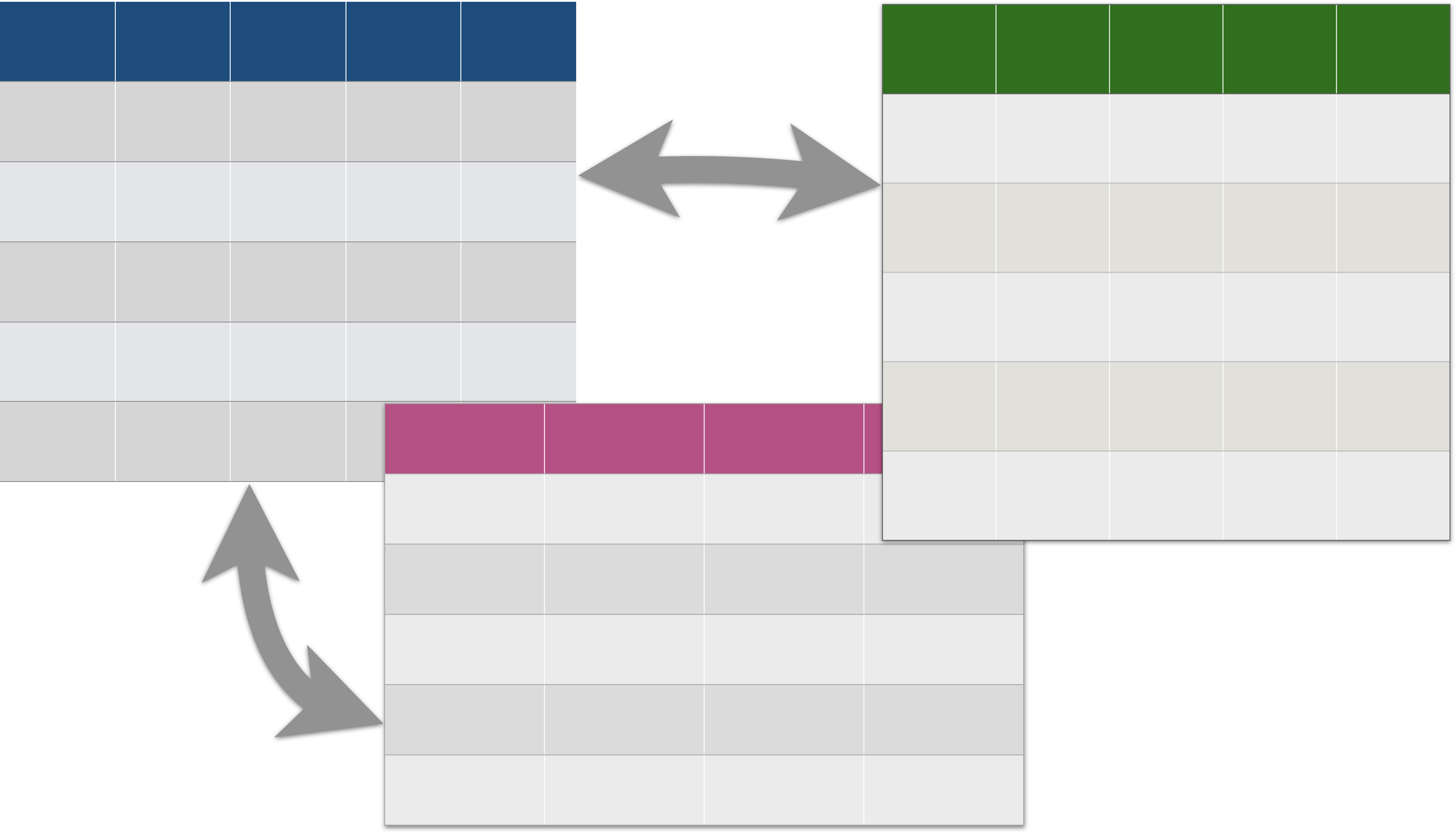
Une base de données contient généralement plusieurs tables (comme un classeur contenant plusieurs feuilles).
Un serveur héberge généralement plusieurs bases (comme une armoire contenant plusieurs classeurs).
Un logiciel permettant d’interagir avec les bases et les tables est un système de gestion de bases de données (SGBD et DBMS en anglais). MySQL et SQLite sont des exemples de SGBD gratuits.
On interagit avec un SGBD par l’intermédiaire de lignes de commandes. On peut aussi utiliser une surcouche graphique (SQLiteStudio par exemple).
Tables
Les tables (ou relations) sont des tableaux à deux dimensions.
- Les colonnes sont appelées attributs. Elles sont caractérisées par un nom et un domaine dans lequel elle prend ses valeurs.
- Les lignes sont appelées enregistrements. Un enregistrement prend une valeur pour chaque attribut de la table. Synonymes : tuple ou n-uplet.
- Et chaque case est un champ.
L’ensemble des valeurs permises pour les champs d’un attribut s’appelle un domaine.
Exemples de domaines : Entiers (INTEGER ou INT), chaînes de caractères de taille fixe (CHAR(X)), chaîne de caractères de taille maximale fixée (VARCHAR(X)), chaîne de caractères de taille libre (TEXT).
Clés
Une clé est un groupe d’attributs (colonnes) minimum qui permet d’identifier de façon univoque un enregistrement (un tuple) dans la table.
Toute table doit comporter au moins une clé, ce qui implique qu’elle ne peut pas contenir deux enregistrements identiques.
Si plusieurs clés existent dans une relation, on en choisit une parmi celles-ci. Cette clé est appelée clé primaire.
La clé primaire est généralement choisie de façon à ce qu’elle soit la plus simple, c’est à dire portant sur le moins d’attributs possibles et sur les attributs ayant des domaines le plus basique possible (entiers ou chaînes courtes typiquement).
On appelle clés candidates l’ensemble des clés d’une relation qui n’ont pas été choisies comme clé primaire (elles étaient candidates à cette fonction).

Rq : il y a plusieurs autres clés candidates : les différentes combinaisons des attributs aboutissant à une concaténation unique.
S’il est impossible de trouver une clé primaire, ou que les clés candidates sont trop complexes, on peut faire appel à une clé artificielle (qui s’oppose à clé naturelle). Une clé artificielle est un attribut supplémentaire ajouté à la table, qui n’est lié à aucune signification, et qui sert uniquement à identifier de façon unique les enregistrements et/ou à simplifier les références de clés étrangères.
C’est généralement ce qui a été fait lorsque les valeurs d’un attribut correspondent au numéro de la ligne (index).
Une clé étrangère est un attribut ou un groupe d’attributs d’une table A apparaissant comme clé primaire dans une table B. Elle matérialise une référence entre les enregistrements de A et de B.
Une clé étrangère d’un enregistrement référence une clé primaire d’un autre enregistrement.
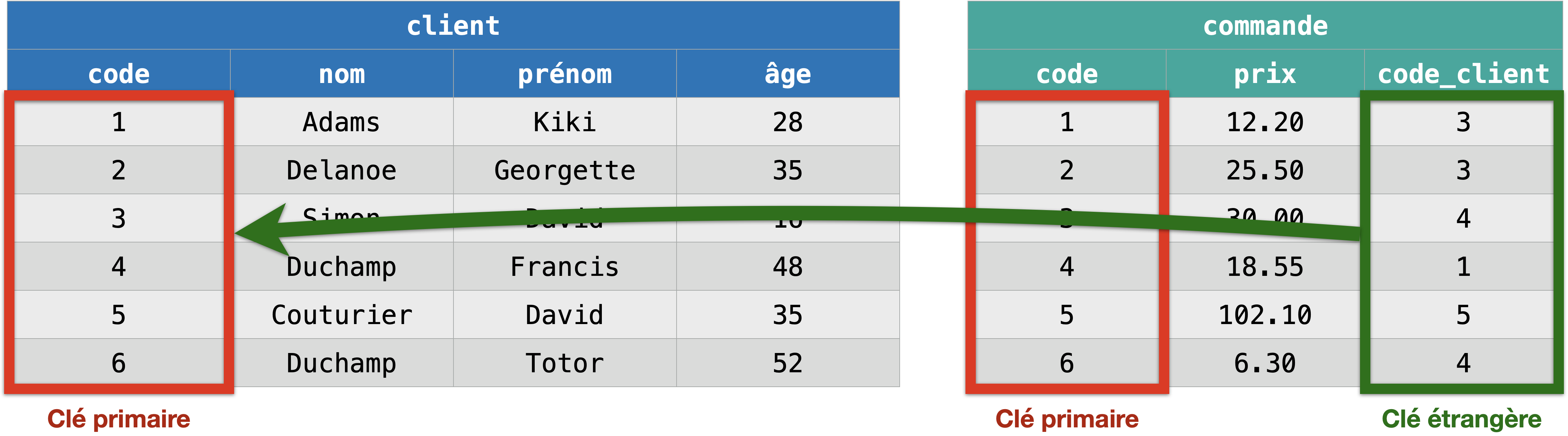
Seule une clé primaire peut être référencée par une clé étrangère, c’est même le seule fonction de la clé primaire : être la clé qui peut être référencée par les clés étrangères.
Représentation graphique
On peut représenter les relations entre tables grâce à des diagrammes sagitaux comme dans l’exemple ci-dessous.
Les clés primaires sont représentées en rouge et les clés étrangères en vert.
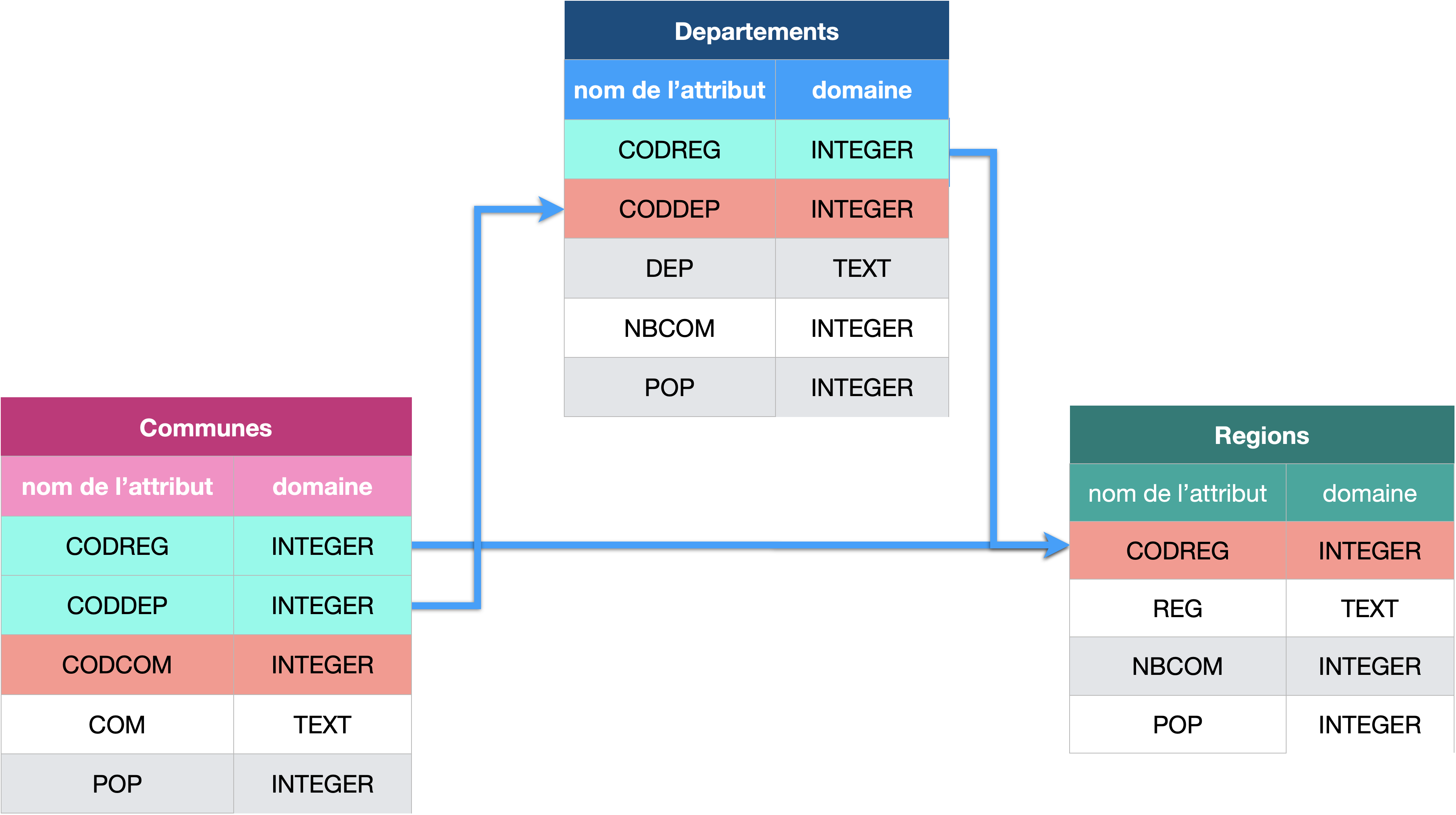
Dans cet exemple, l’attribut CODCOM est insuffisant pour servir de clé primaire à la table Communes (car il y a des valeurs redondantes), mais la combinaison des attributs CODCOM et CODDEP donne bien un code unique et donc convient.
Opérations sur les données
Dans une base de données relationnelle, on extrait et on traite les données en utilisant un jeu d’opérations mathématiques. Il y a huit opérations principales, que l’on peut répartir en opérations ensemblistes et opérations relationnelles.
Opérations ensemblistes
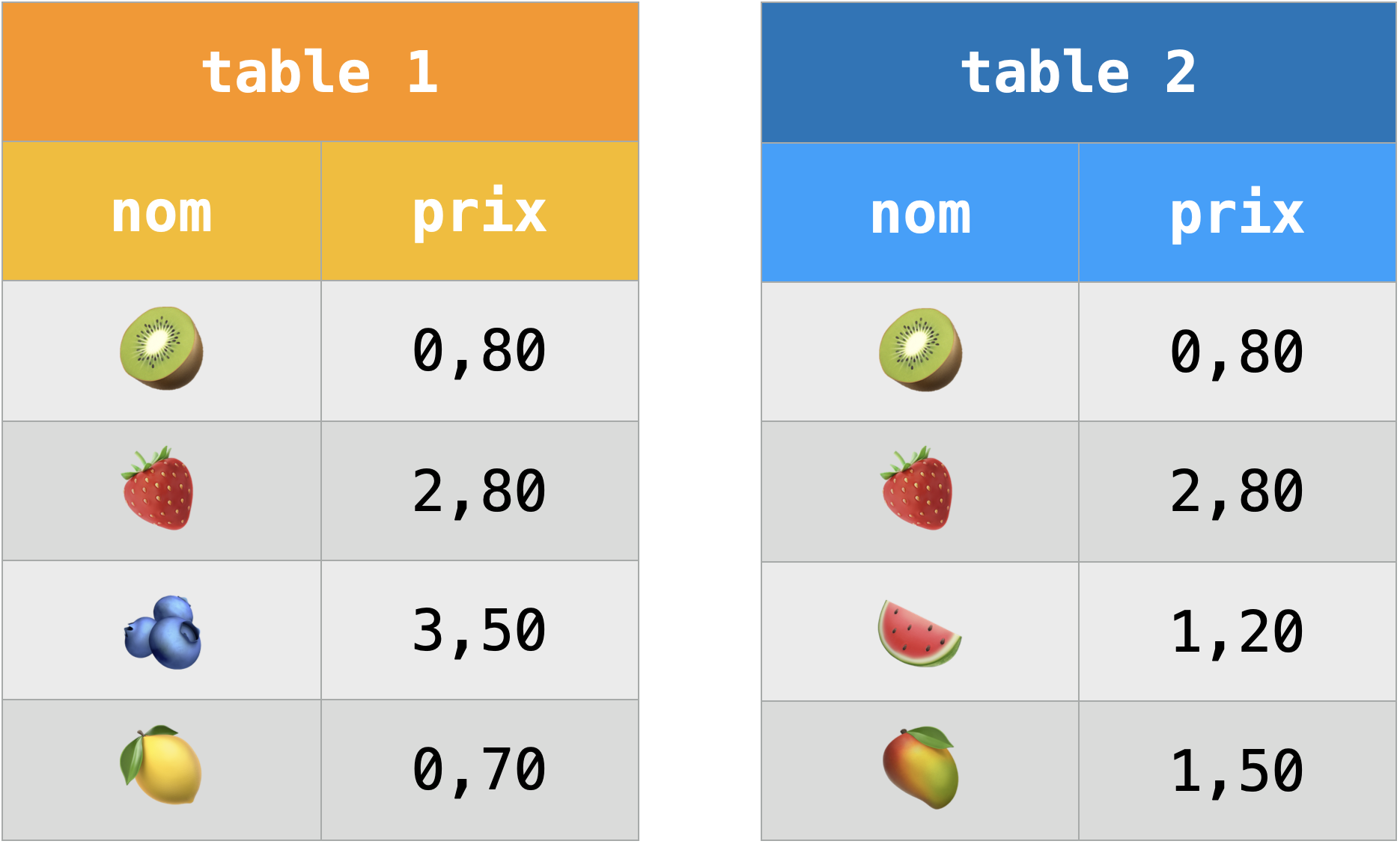
Union :

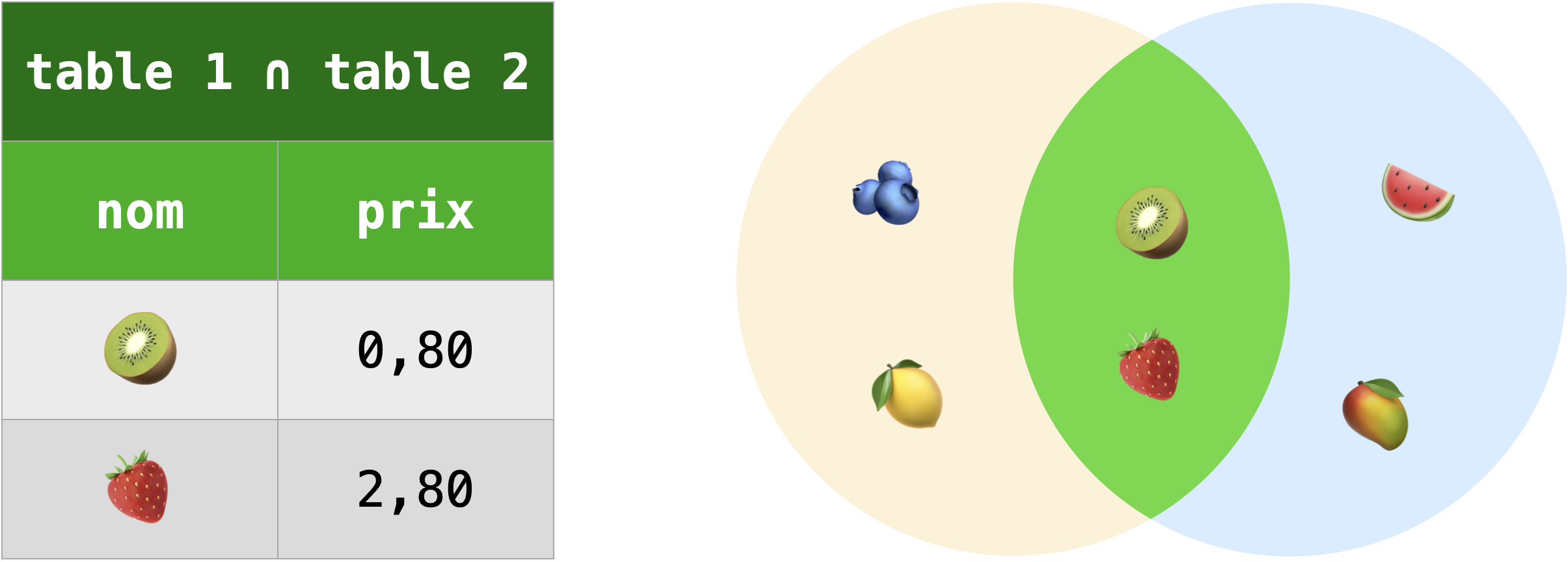
Intersection :
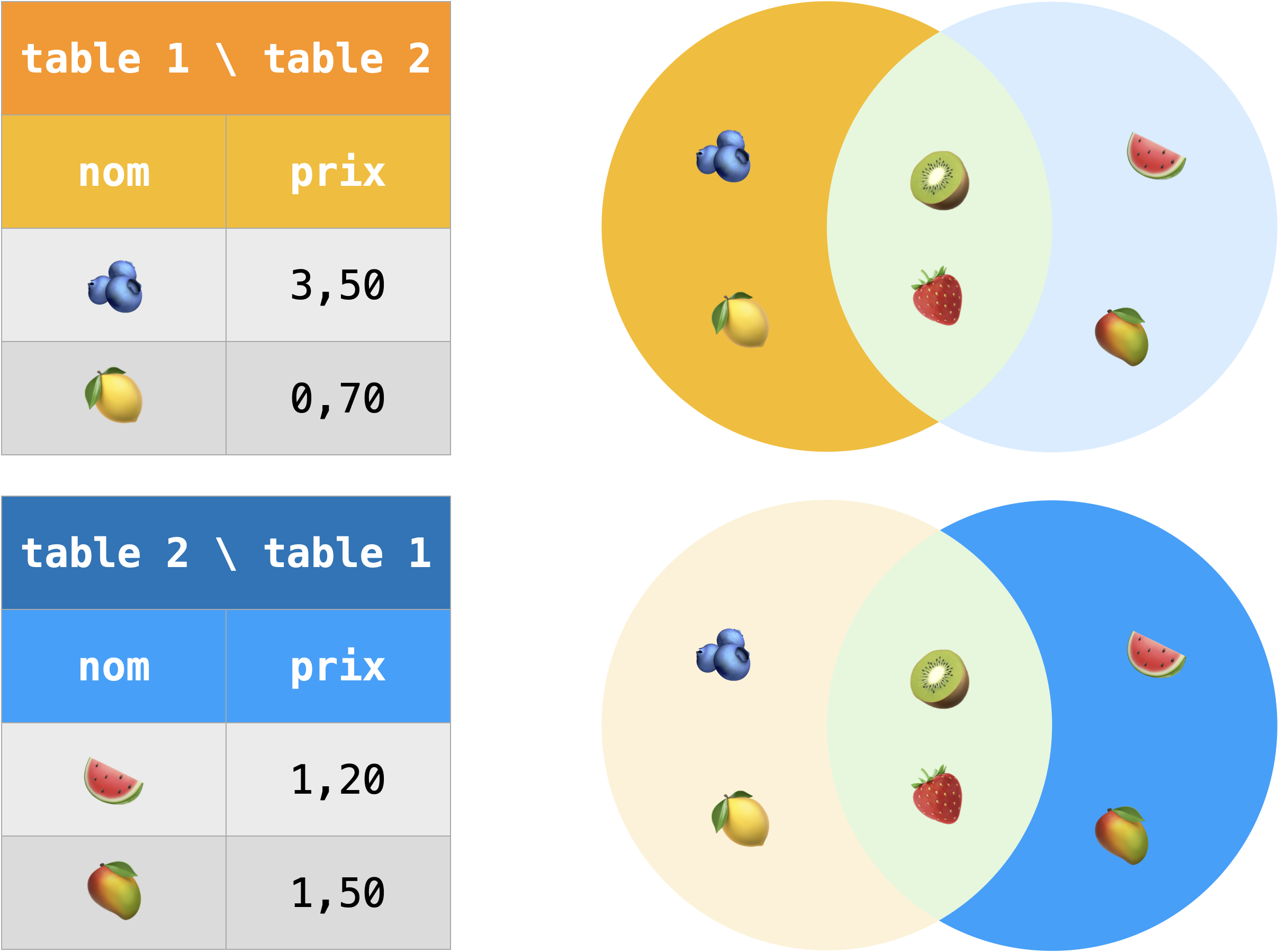
Différence :
Produit cartésien :
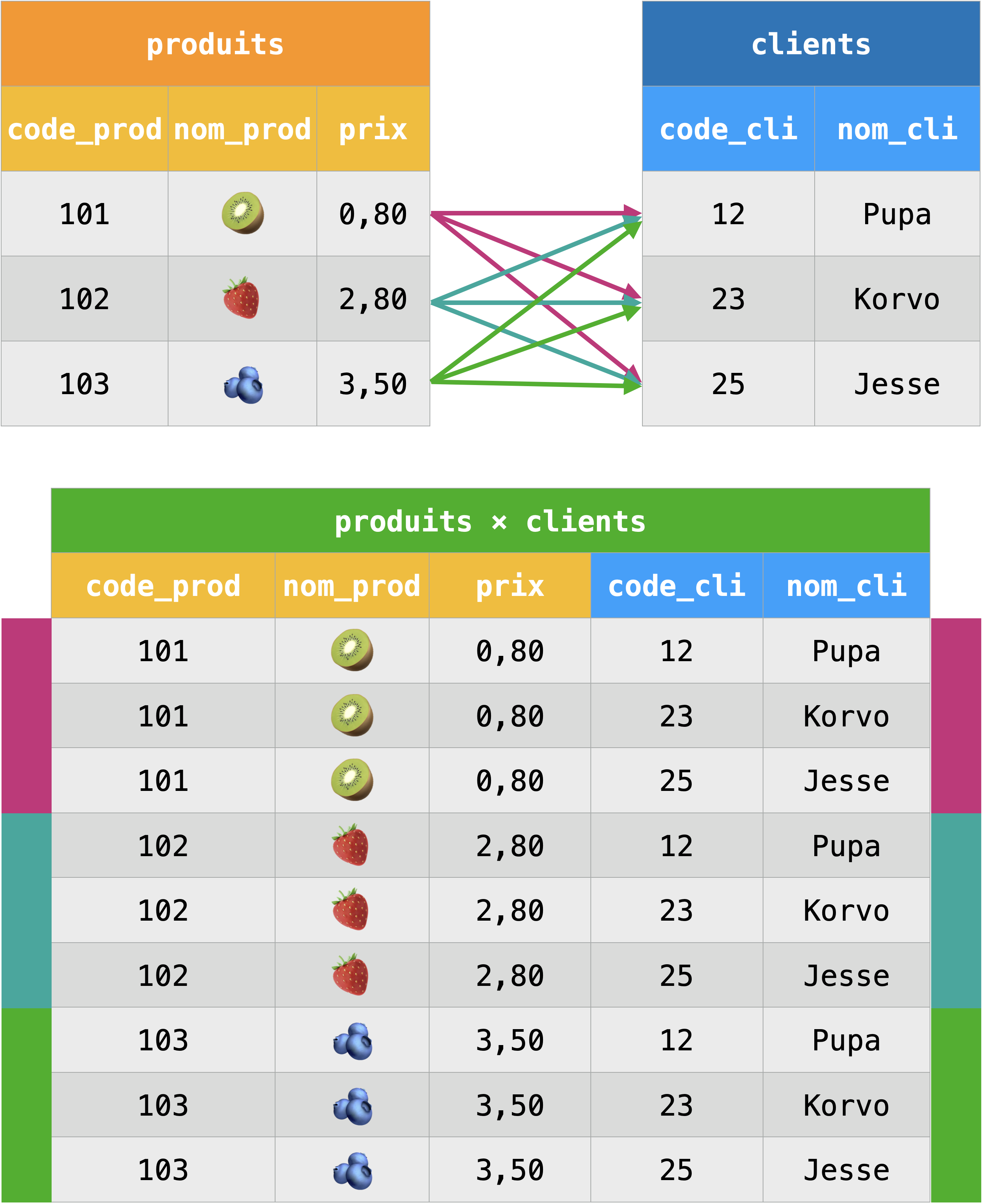 Le nombre de lignes de la table résultat vaut le produit des nombres de lignes de chacune des tables.
Le nombre de lignes de la table résultat vaut le produit des nombres de lignes de chacune des tables.
Division :
C’est l’opération inverse du produit cartésien. Pour trouver le quotient de la division de la table 1 par la table 2, on cherche avec quoi il faudrait faire le produit de la table 2 pour obtenir les lignes de la table 1 contenant les champs de la table 2.

Opérations relationnelles
Projection :
La projection extrait une ou plusieurs colonnes (attributs) d’une table.
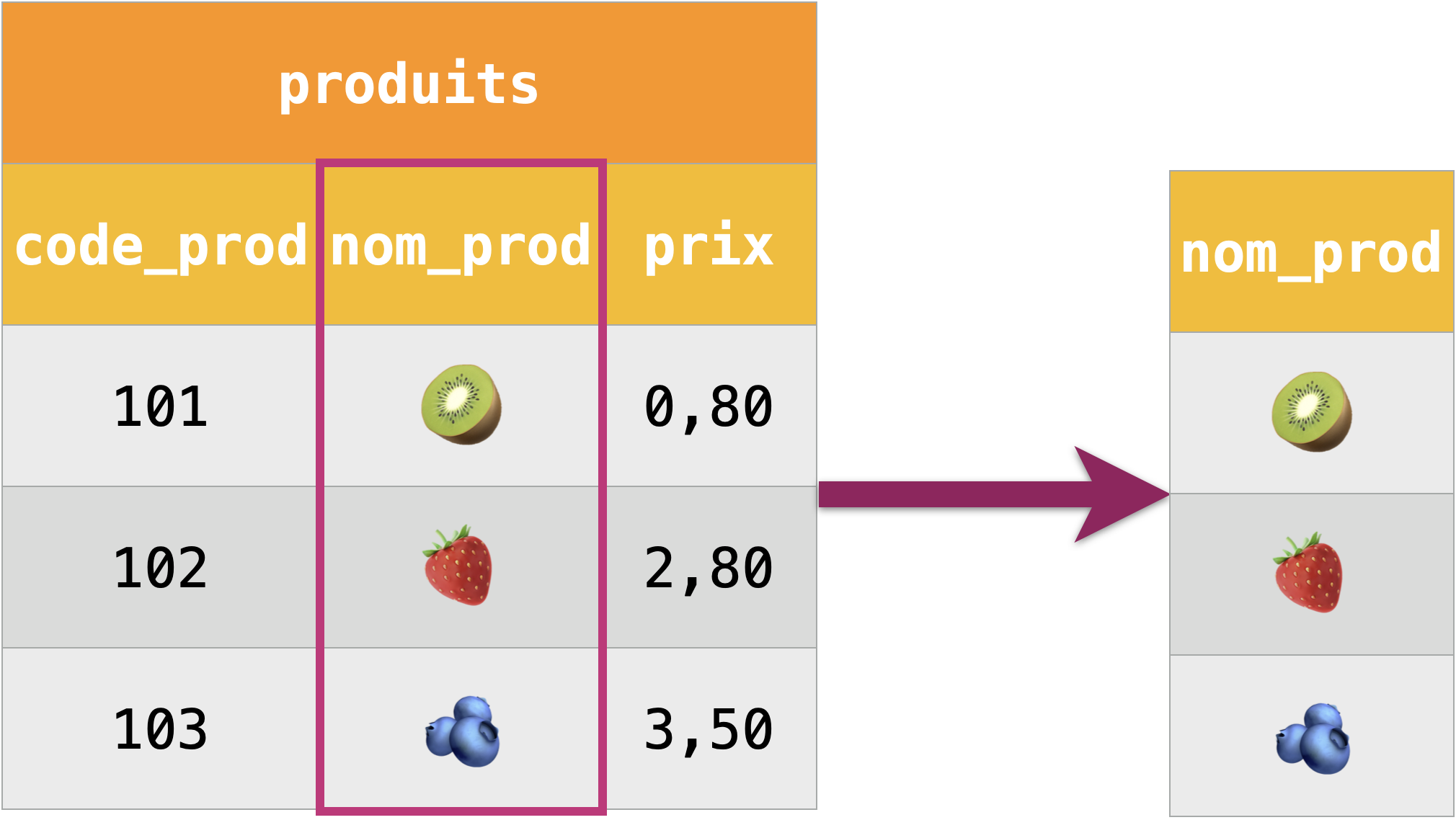
Restriction :
La restriction (aussi appelée sélection) extrait une ou plusieurs lignes (enregistrements) d’une table.
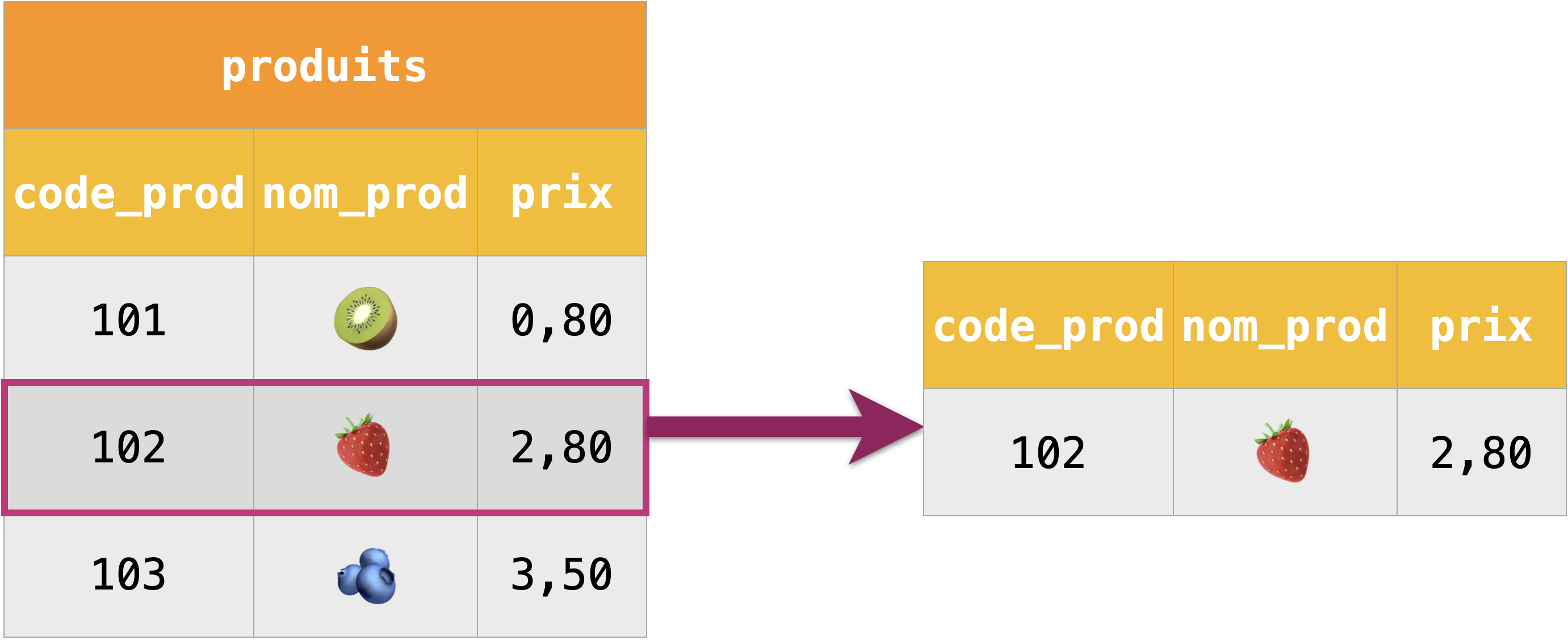
Jointure interne :
Une jointure interne permet de combiner deux tables en se servant d’une colonne dans chaque table ayant des valeurs en commun. On suture alors sur ces valeurs communes et on laisse tomber les lignes n’ayant pas de correspondance d’une table à l’autre.
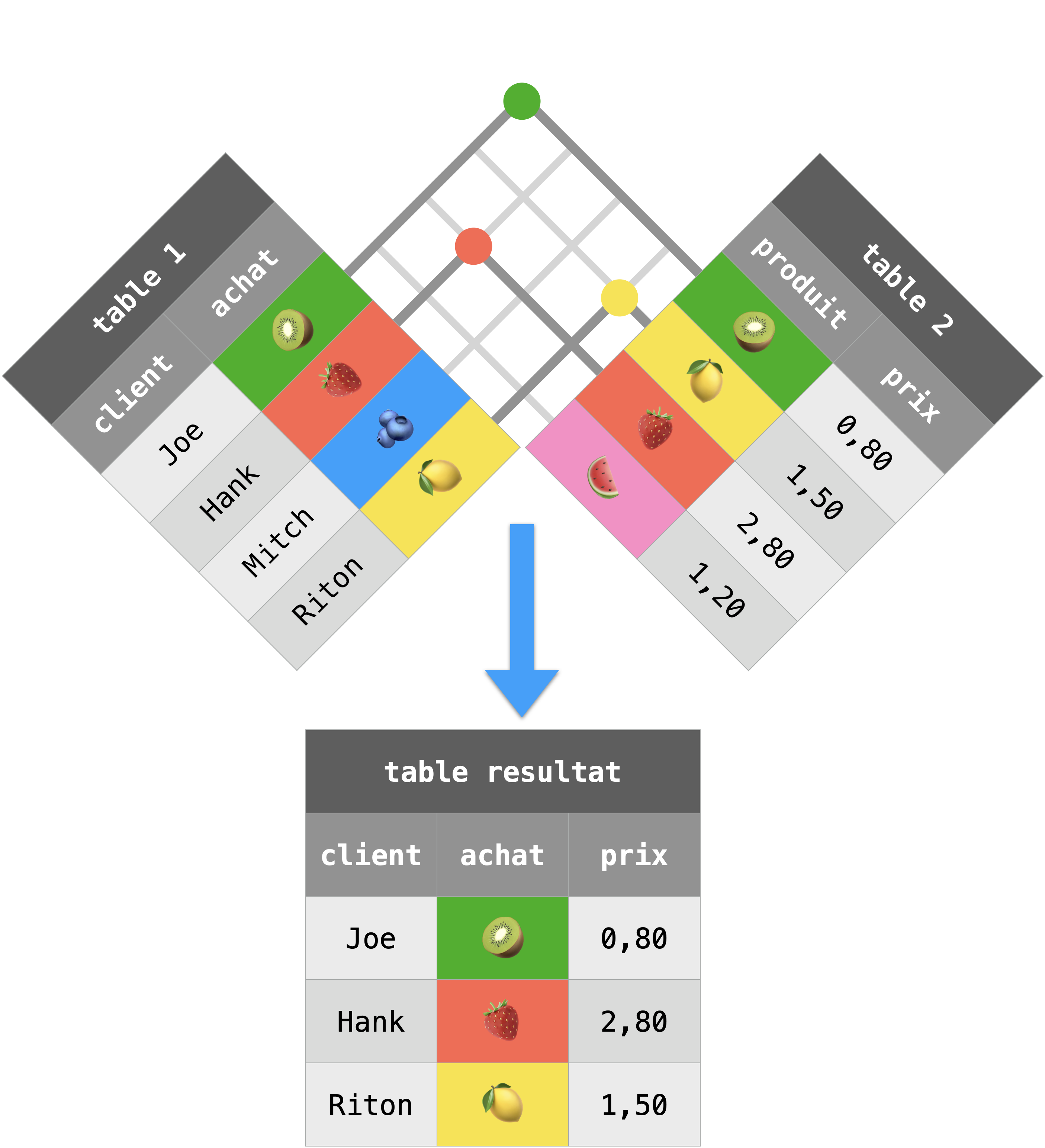
Si on joint sur la clé étrangère d’une table correspondant à la clé primaire de l’autre table, toutes les lignes seront présentes dans le résultat !
SQL
Pour dialoguer avec une base de données relationnelle, on utilise le langage SQL (Structured Query Language).
On entre des requêtes (ou instructions, query en anglais), qui ressemble à des phrases (terminées par des points-virgules). Chaque requête est constituée de clauses faites de commandes (ou mots clefs) suivies d’arguments dont certains peuvent être remplacés par des jokers.
Les commandes sont des mots anglais, ce qui donne à SQL l’apparence d’une langue naturelle.
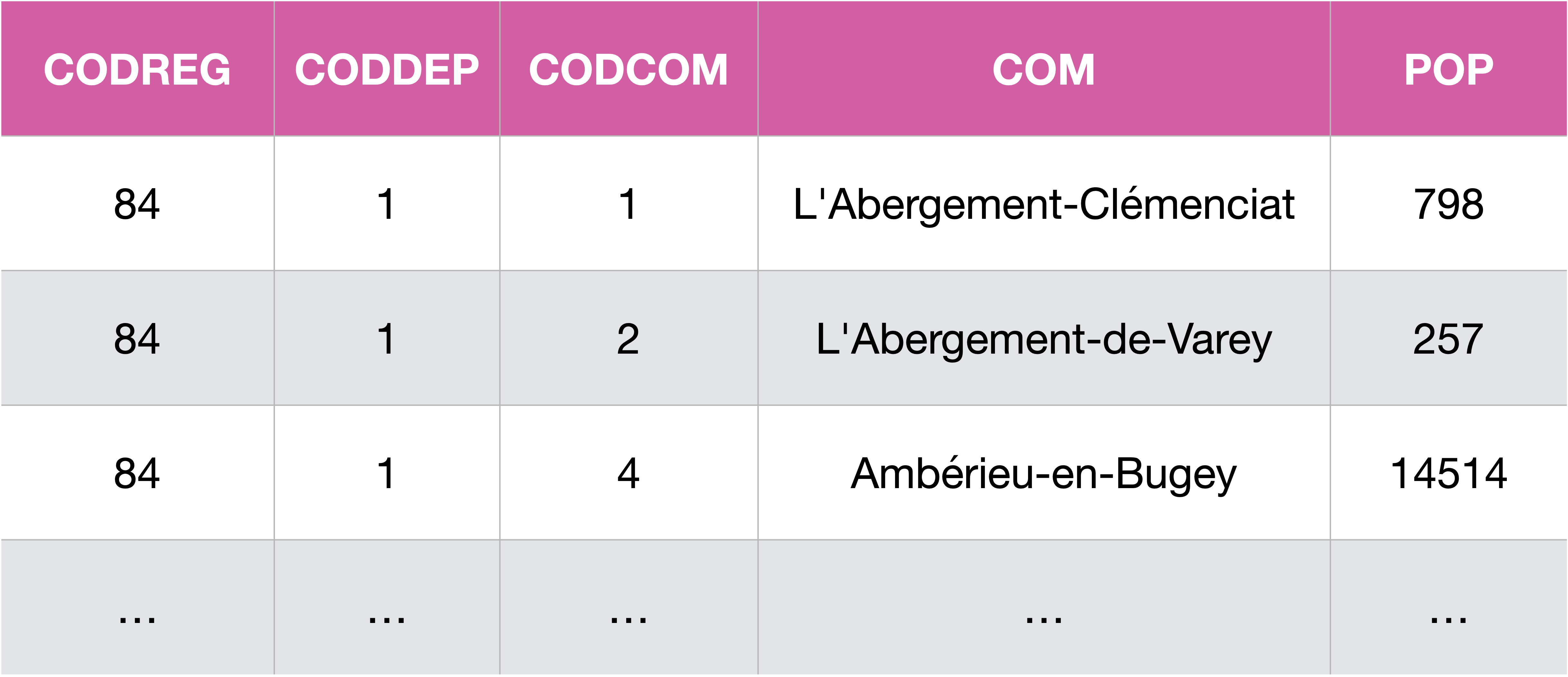
Pour illustrer les différentes requêtes, on va utiliser la base de données dont le modèle a été aperçu plus haut :
Et voici un extrait des trois tables :
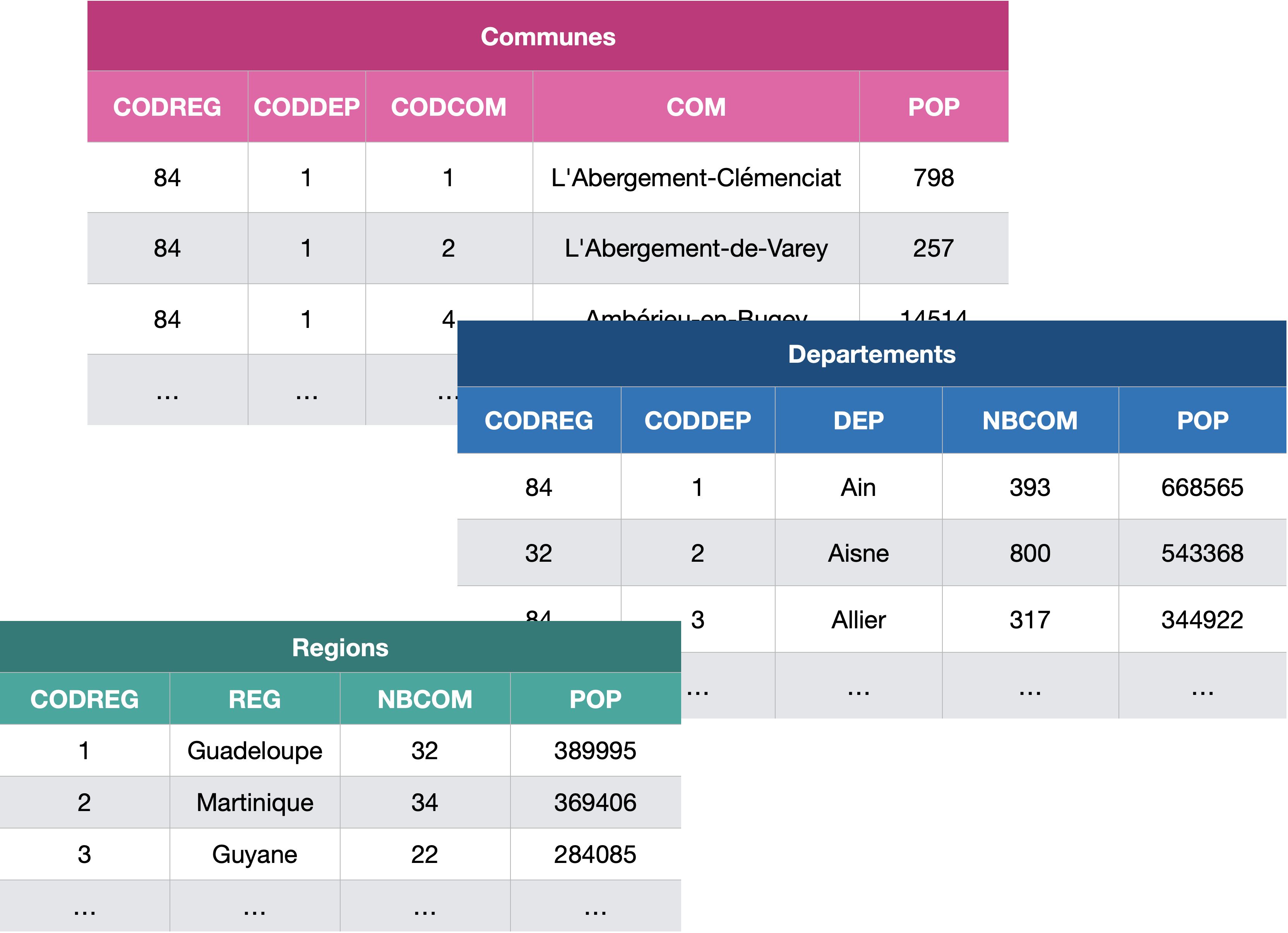
Rq : NBCOM désigne le nombre de communes (dans un département ou dans une région) et POP la population (dans une commune, un département, ou une région).
Cette base est issue des données “Populations légales 2019” de l’INSEE publiées le 12/01/2022. Elle a été construite via SQLite et elle est intégrée au repo du TP si vous voulez interagir avec et reproduire les exemples.
SELECT
C’est la commande la plus importante ! Elle permet de rechercher des données dans une table (ou plusieurs) en précisant des conditions.
SELECT opère un mélange entre une projection et une restriction.
La syntaxe de base est :
SELECTliste d’attributs projeté
FROMliste de tables
WHEREcondition de la restriction
- La partie
SELECTindique le sous-ensemble des attributs qui doivent apparaître dans la réponse. - La partie
FROMdécrit les tables (relations) qui sont utilisables dans la requête (c’est à dire l’ensemble des attributs que l’on peut utiliser). - La partie
WHEREexprime les conditions que doivent respecter les attributs d’une ligne (d’un tupe) pour pouvoir être dans la réponse. Une condition est un prédicat et par conséquent renvoie un booléen. Cette partie est optionnelle.
Pour récupérer toutes les colonnes de la table commune :
SELECT *
FROM Communes;
le symbole * sert de joker.
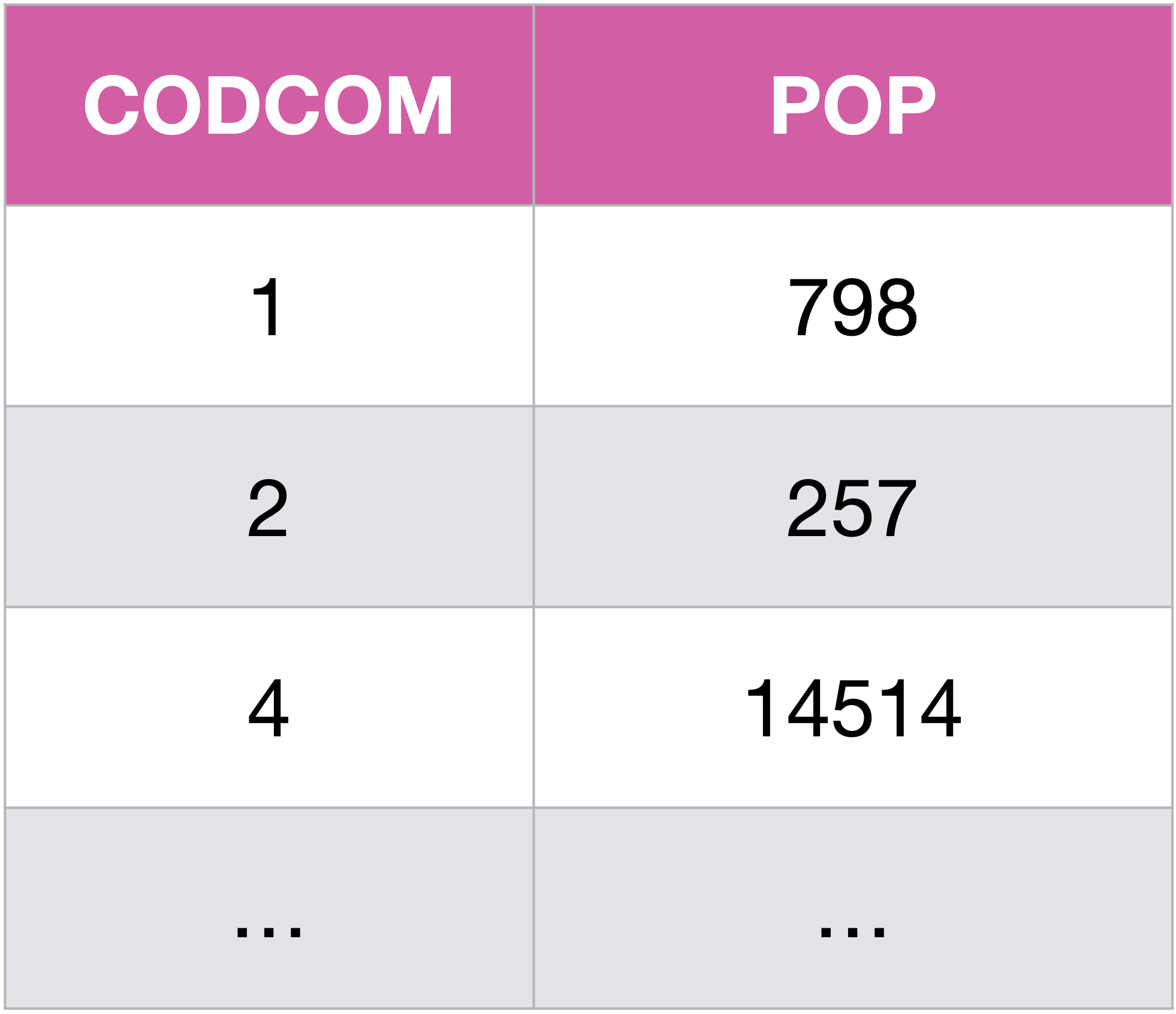
Pour récupérer seulement les colonnes CODCOM et POP de la table commune (on opère ainsi une projection) :
SELECT CODCOM, POP
FROM Communes;
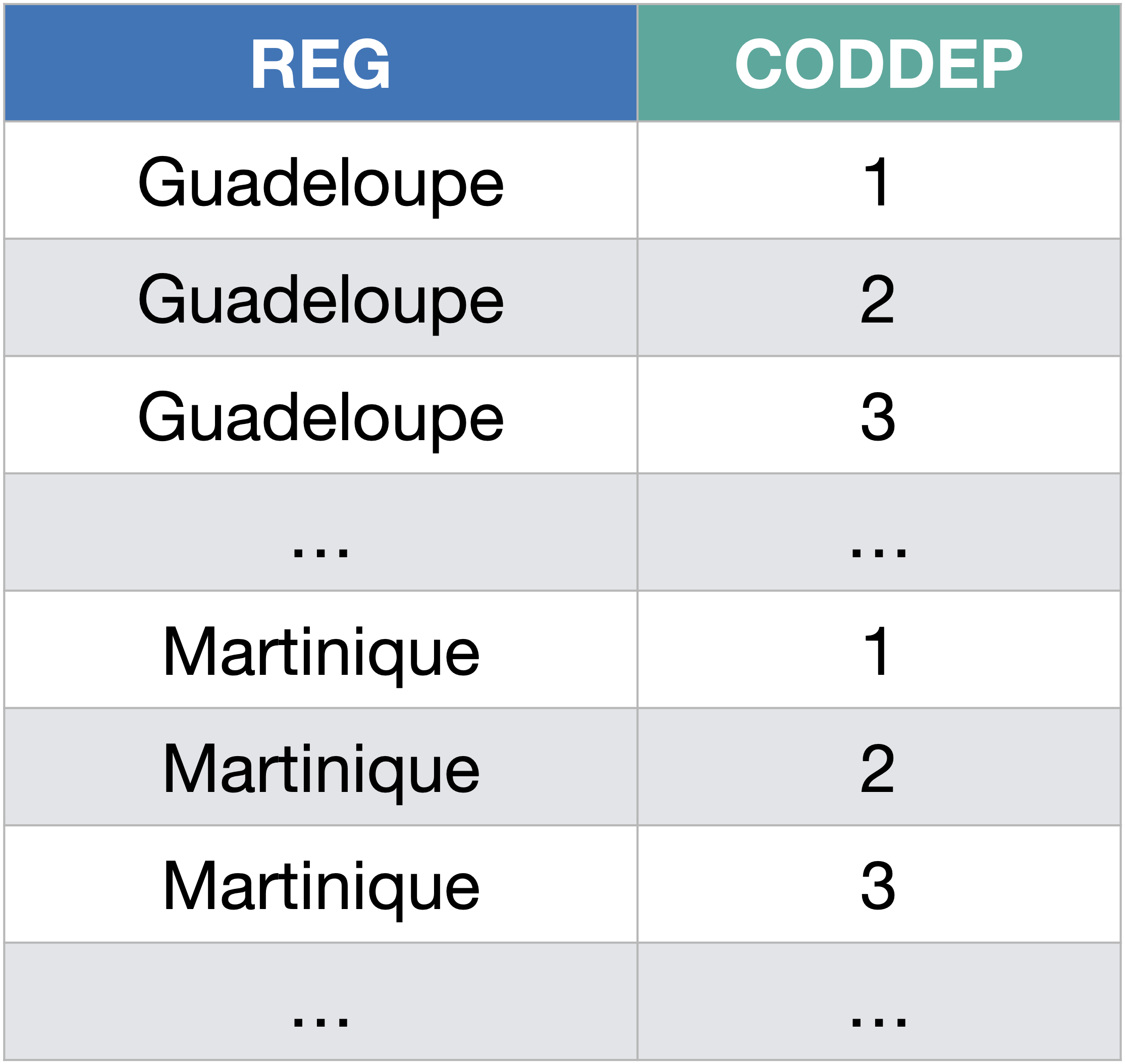
On peut aussi très simplement opérer le produit cartésien de deux tables en sélectionnant des attributs de chacune des tables :
SELECT Regions.REG, Departements.CODDEP
FROM Regions, Departements;
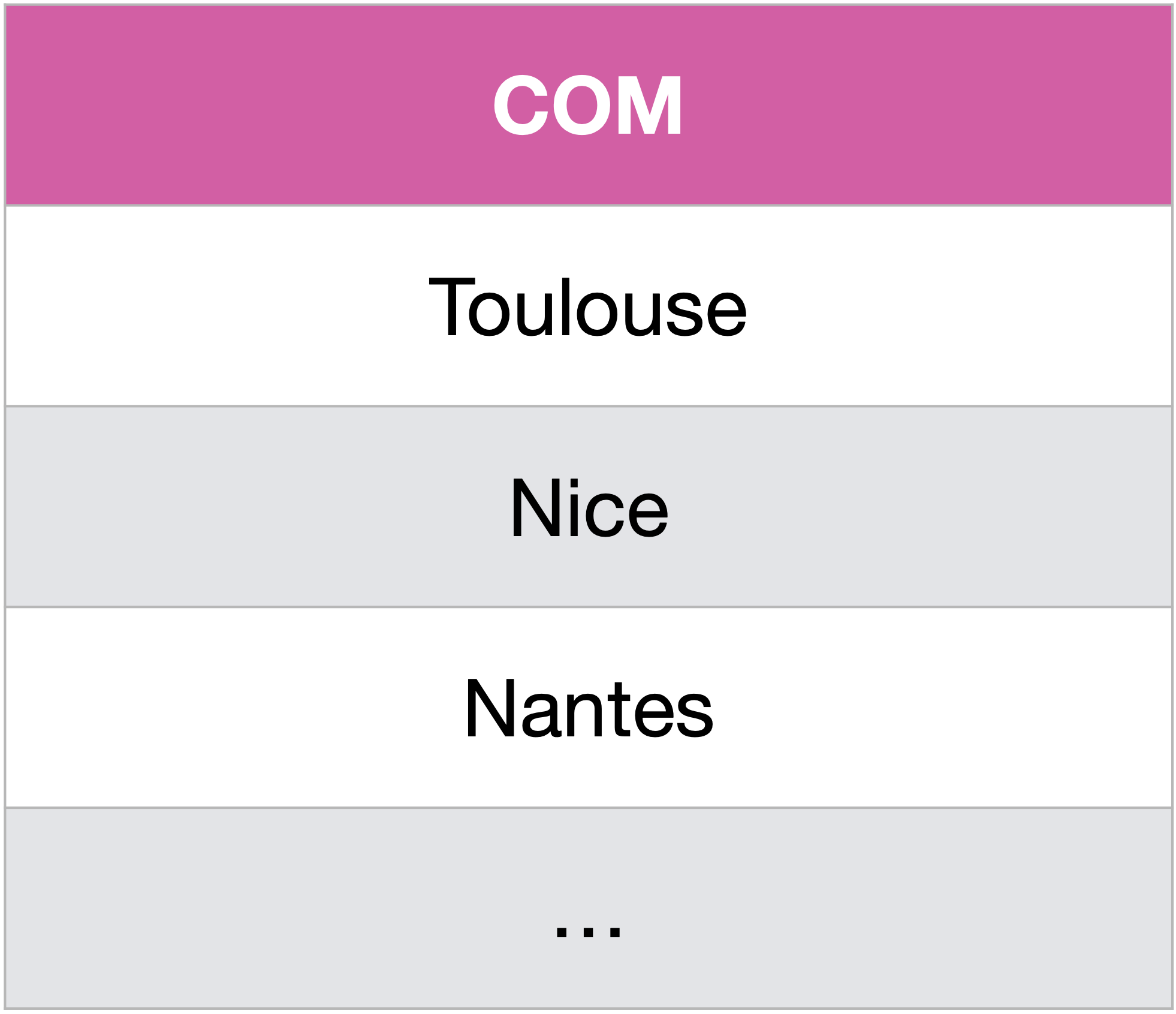
Pour récupérer la colonne COM triée suivant la colonne POP en ordre ascendant (par défaut), on utilise la clause ORDER BY :
SELECT COM
FROM Communes
ORDER BY POP;
 Aucun habitant à Cumières-le-Mort-Homme… le nom semble approprié 😨
Aucun habitant à Cumières-le-Mort-Homme… le nom semble approprié 😨
Et pout un tri en ordre descendant, on ajoute le mot clef DESC :
SELECT COM
FROM Communes
ORDER BY POP DESC;
 Où sont passées Lyon, Paris, Marseille ?
Où sont passées Lyon, Paris, Marseille ?
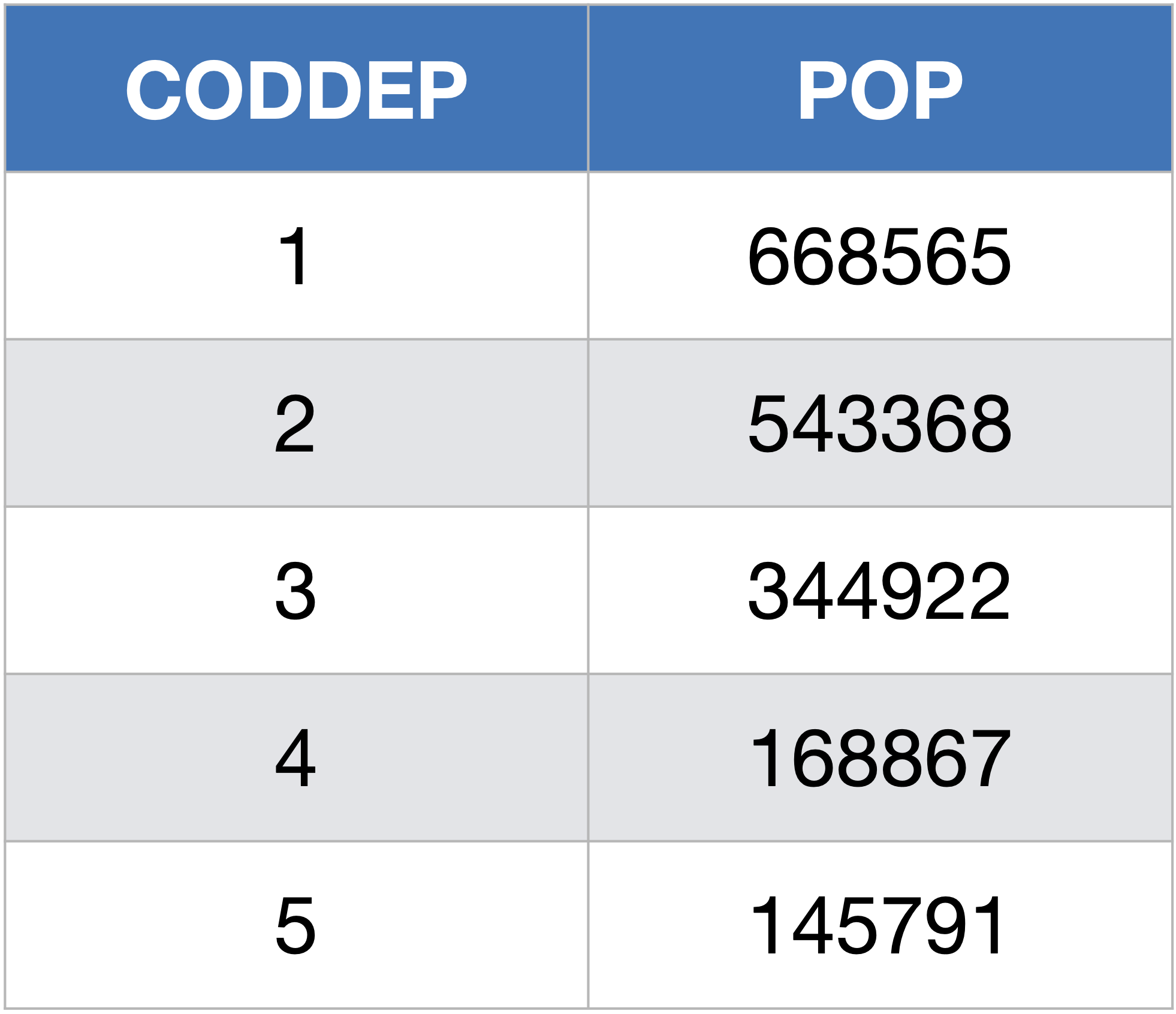
Pour récupérer seulement un nombre limité d’enregistrements (de lignes), on utilise le mot clef LIMIT :
SELECT CODDEP, POP
FROM Departements
LIMIT 5;
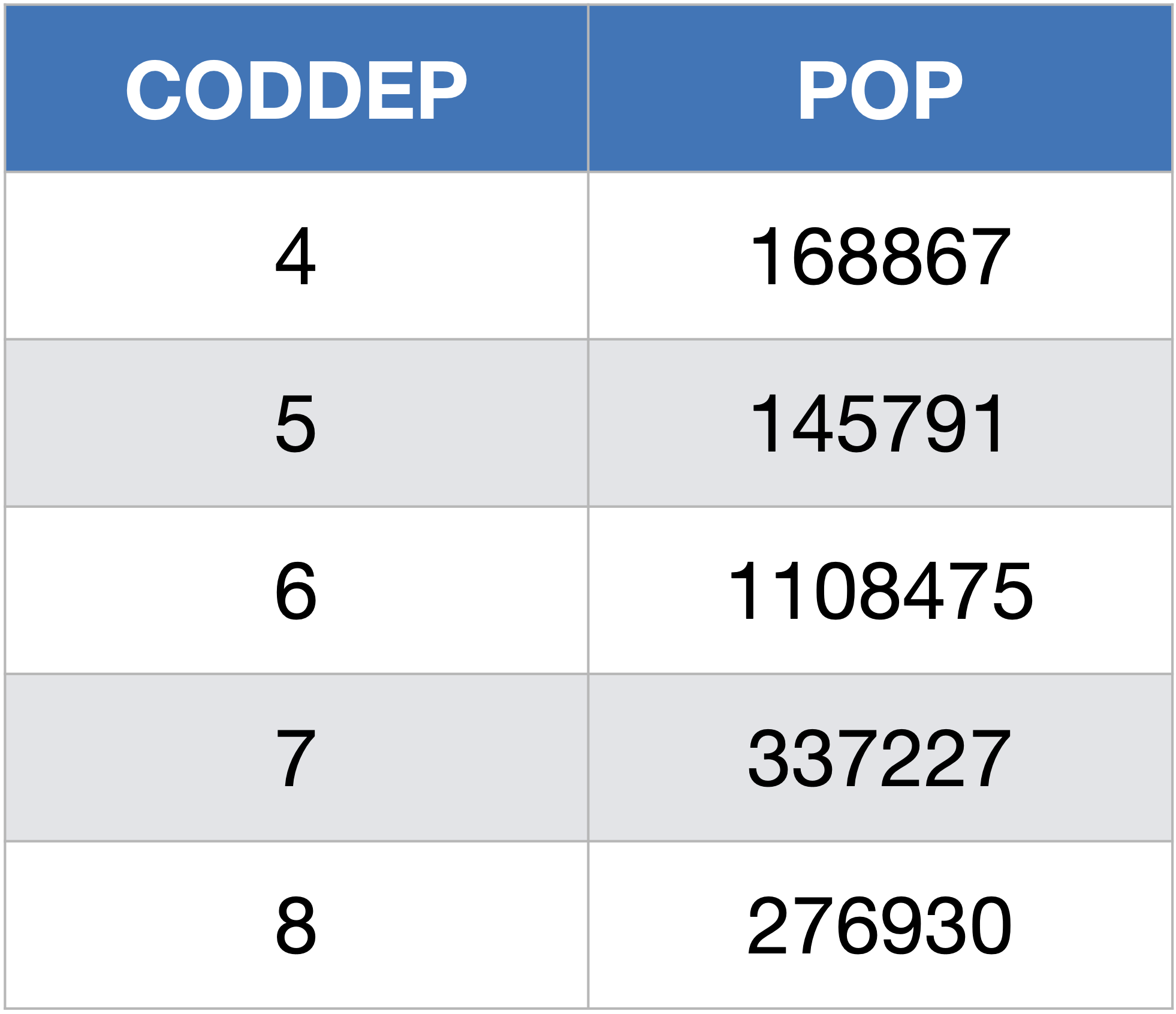
Et on peut aussi décaler l’ensemble des résultats d’un certain nombre de lignes grâce au mot clef OFFSET.
SELECT CODDEP, POP
FROM Departements
LIMIT 5 OFFSET 3;
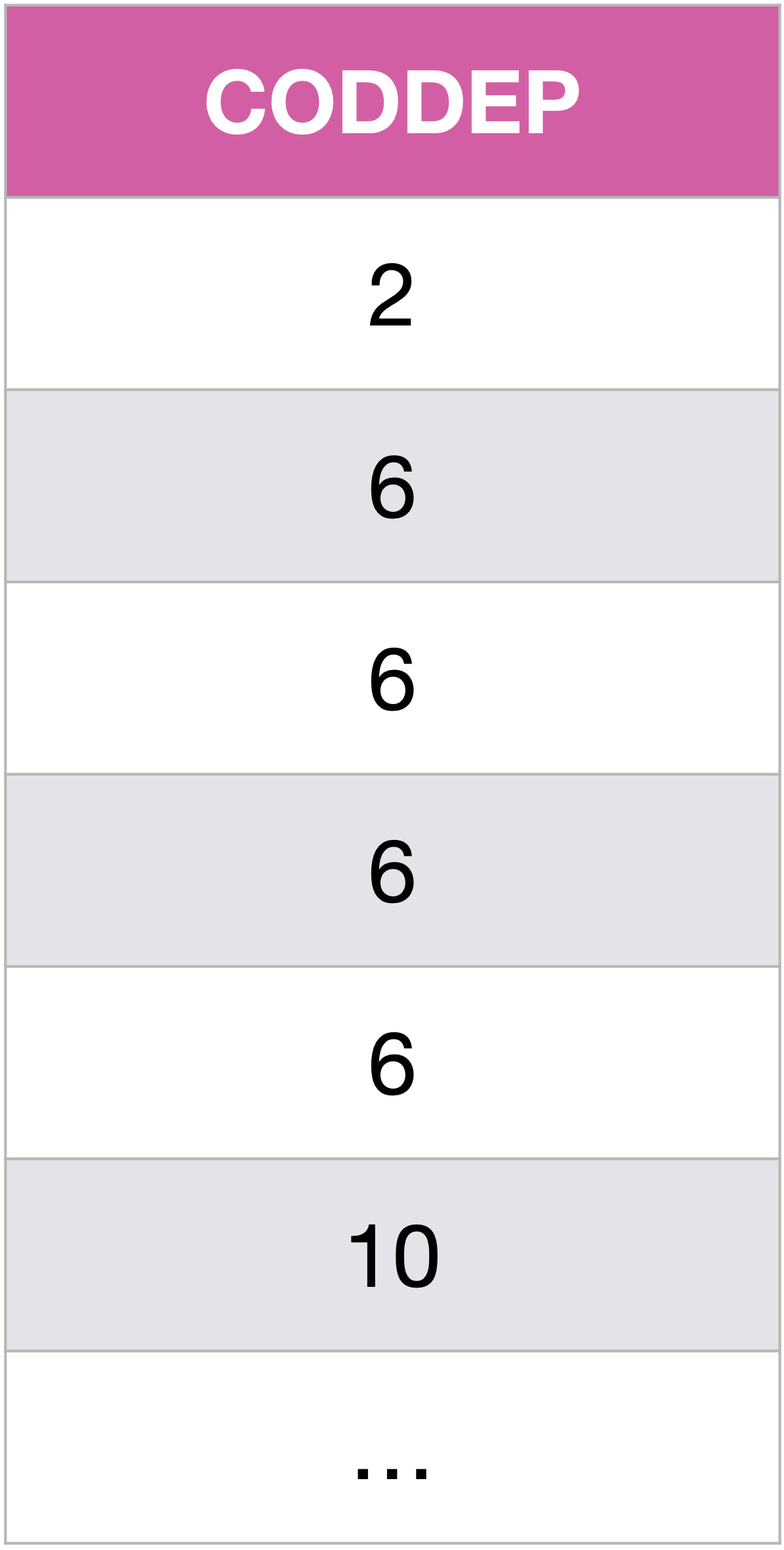
Utilions maintenant WHERE pour filtrer les résultats (on opère alors une restriction/sélection).
Sélectionnons les codes départements des communes de plus de $50\,000$ habitants :
SELECT CODDEP
FROM Communes
WHERE POP > 50000;
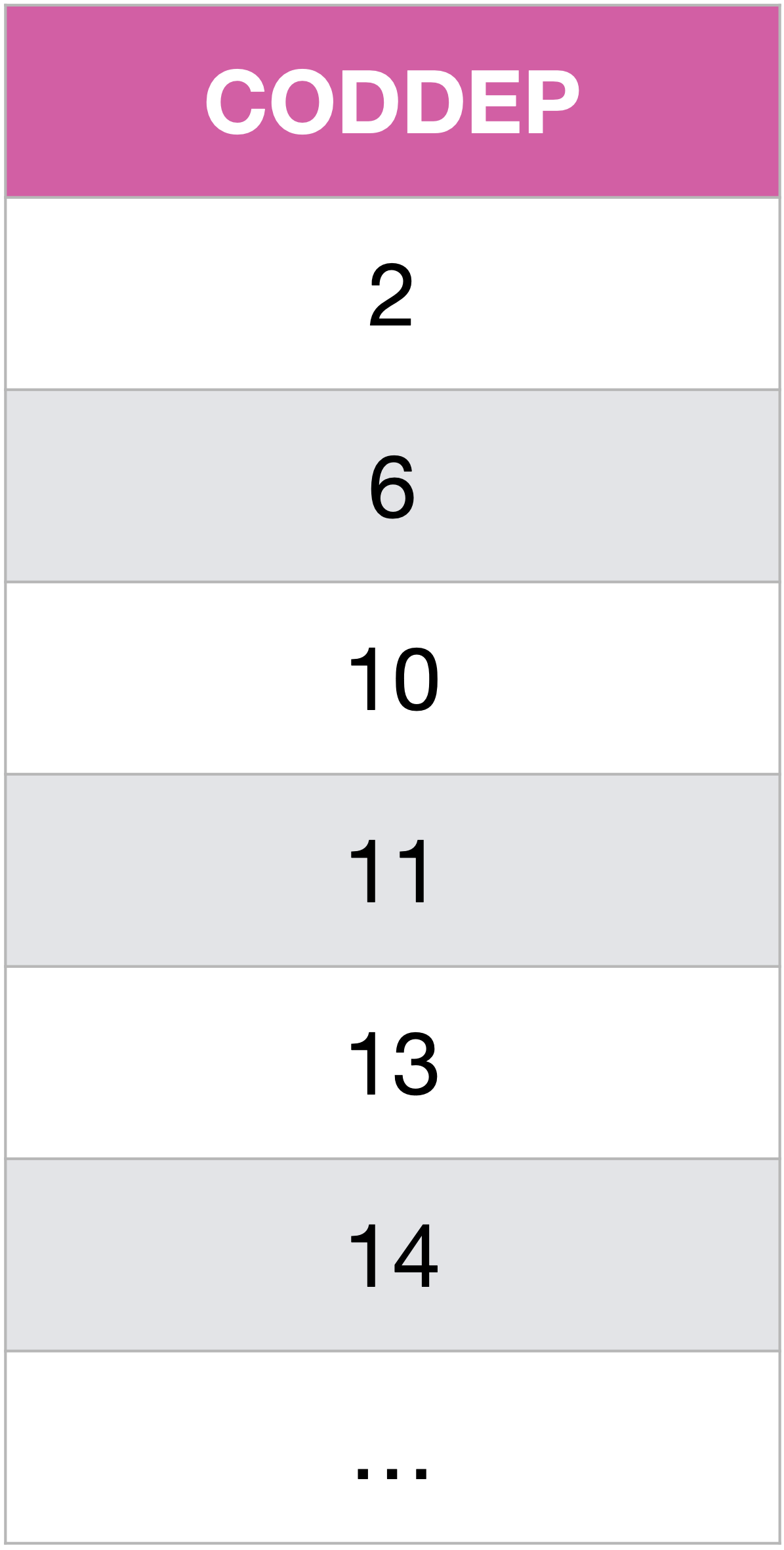
On remarque sur le résultat précédent qu’il y a des résultats redondants… Pour éliminer les doublons, on peut utiliser SELECT DISTINCT.
SELECT DISTINCT CODDEP
FROM Communes
WHERE POP > 50000;
La clause WHERE d’une instruction de sélection est définie par une condition. Une telle condition s’exprime à l’aide d’opérateurs de comparaison et d’opérateurs logiques. Le résultat d’une expression de condition est toujours un booléen.
Les opérateurs au programme :
| Opérateur | Signification |
|---|---|
= |
égal à |
<> |
différent de |
< |
inférieur à |
<= |
inférieur ou égal à |
> |
supérieur à |
>= |
supérieur ou égal à |
AND |
et |
OR |
ou (inclusif) |
NOT |
non |
IN |
appartient à |
Lorsque la condition porte sur une chaîne de caractères, deux jokers sont utilisable : % pour désigner une chaîne quelconque de taille non fixée et _ pour désigner un unique caractère quelconque. Mais il faut alors utiliser l’opérateur de comparaison LIKE plutôt que =. C’est a priori hors programme.
SELECT COM
FROM Communes
WHERE COM LIKE 'Paris%';
SELECT COM
FROM Communes
WHERE COM LIKE '%Arrondissement';
SELECT COM
FROM Communes
WHERE COM LIKE '_ours';

Afin de décrire un attribut d’une table en particulier (dans le cas d’une requête portant sur plusieurs tables notamment), on utilise la notation table.attribut.
SELECT Communes.COM, Departements.DEP, Regions.REG
FROM Communes, Departements, Regions
WHERE Communes.CODDEP = Departements.CODDEP AND Communes.CODREG = Departements.CODREG;
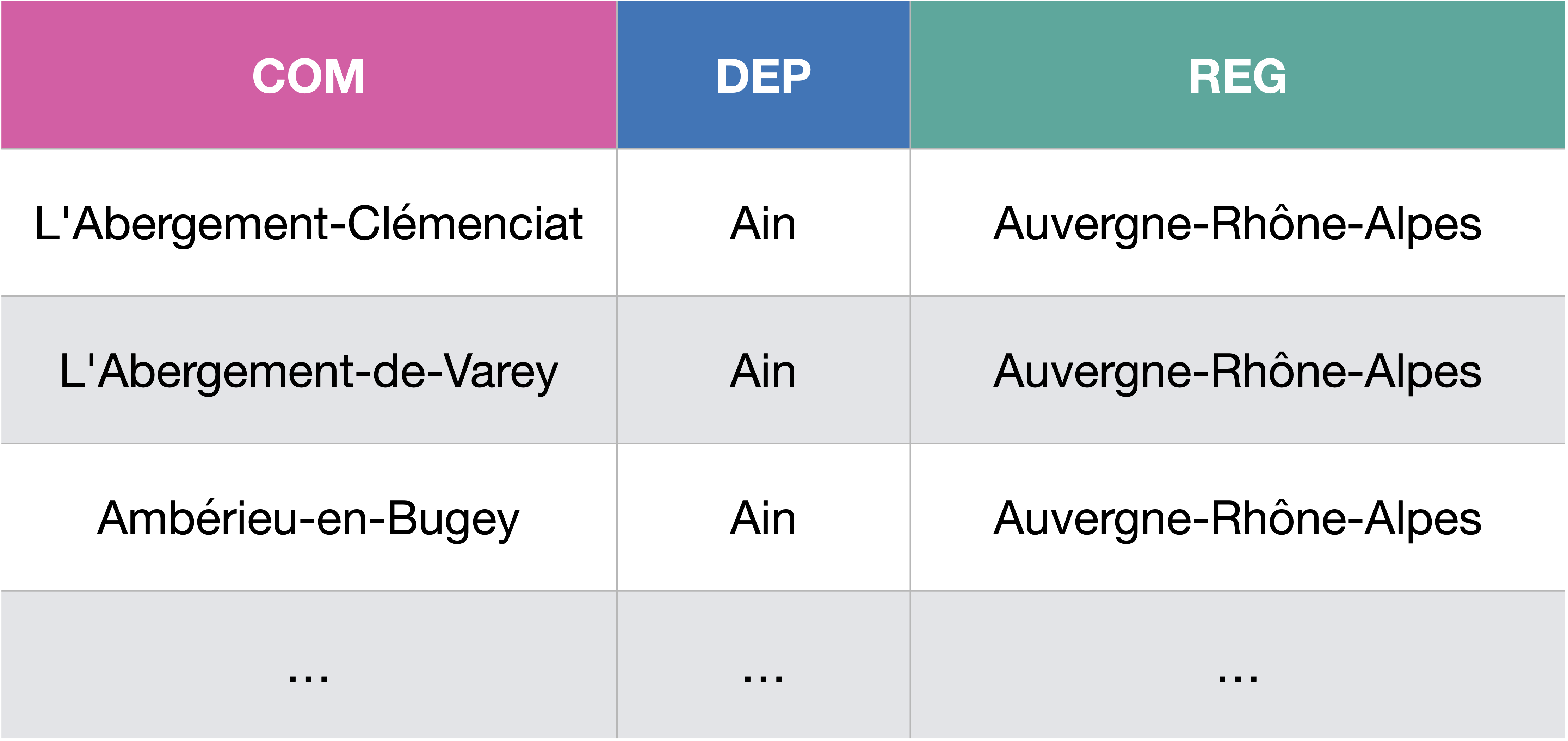
On peut aussi renommer les tables et les attributs par des alias grâce au mot clef AS afin d’en simplifier la syntaxe.
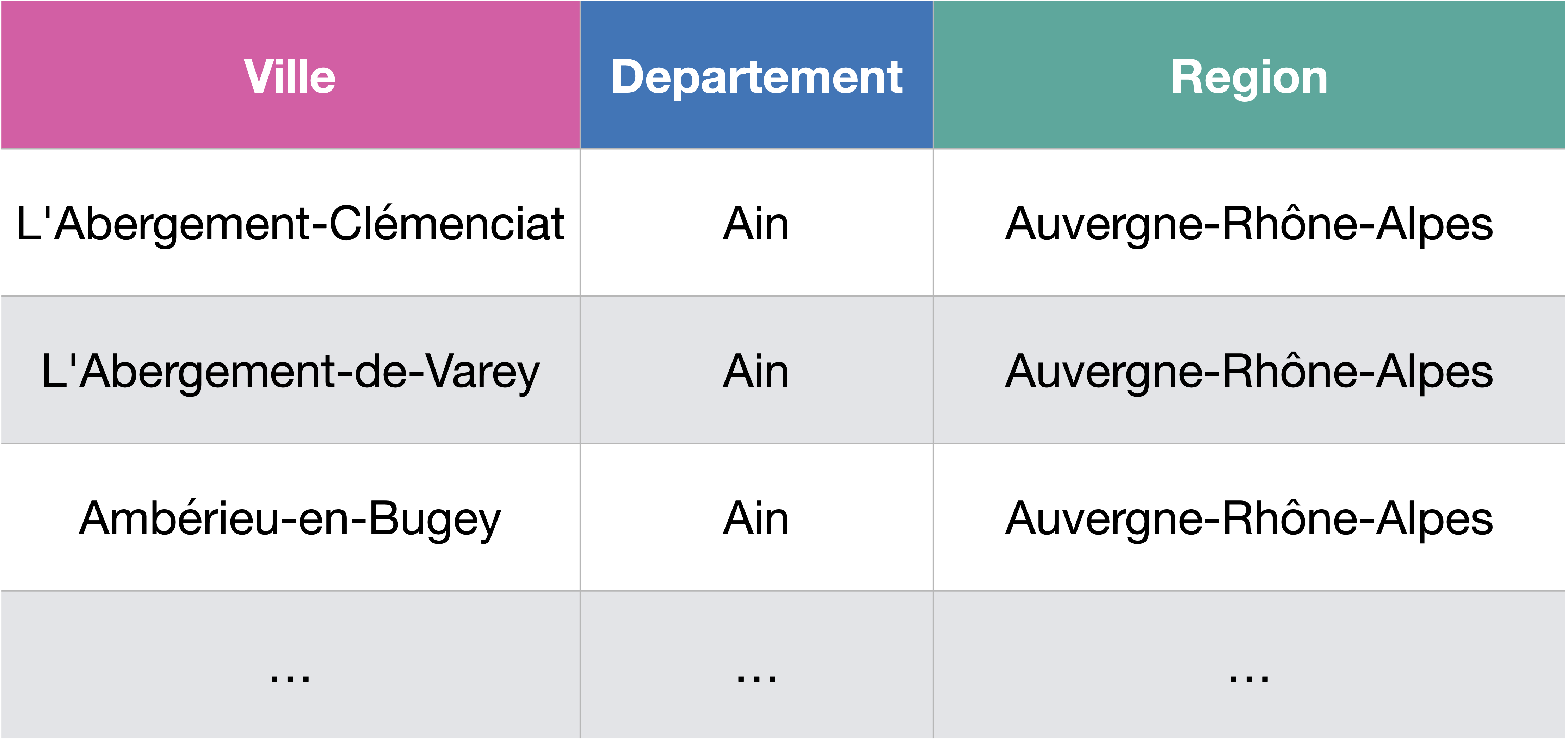
Réécrivons par exemple la requête précédente. Les alias servent à la fois à simplifier le nom des tables (raccourcis définis dans le FROM, mais qu’on peut déjà utiliser dans le SELECT) ou rendre le nom des attributs plus parlants (dans le SELECT).
SELECT Co.COM AS ville, De.DEP AS departement, Re.REG AS region
FROM Communes AS Co, Departements AS De, Regions AS Re
WHERE Co.CODDEP = De.CODDEP AND Co.CODREG = Re.CODREG;
Agrégation
Fonctions d’agrégation
Les fonctions d’agrégation sont des fonctions de type statistique qui prennent en argument un ou plusieurs attributs et qui s’appliquent à l’ensemble des champs ainsi sélectionnés.
Les fonctions d’agrégation ont pour résultat une valeur atomique (pas un groupe) comme un nombre ou une chaîne.
Les fonctions au programme sont :
| Fonction | renvoie |
|---|---|
MIN |
la valeur minimale |
MAX |
la valeur maximale |
SUM |
la somme |
AVG |
la moyenne |
COUNT |
le nombre d’enregistrements |
SELECT COUNT(*) AS nb_communes
FROM Communes;

SELECT MIN(POP), MAX(POP)
FROM Regions;
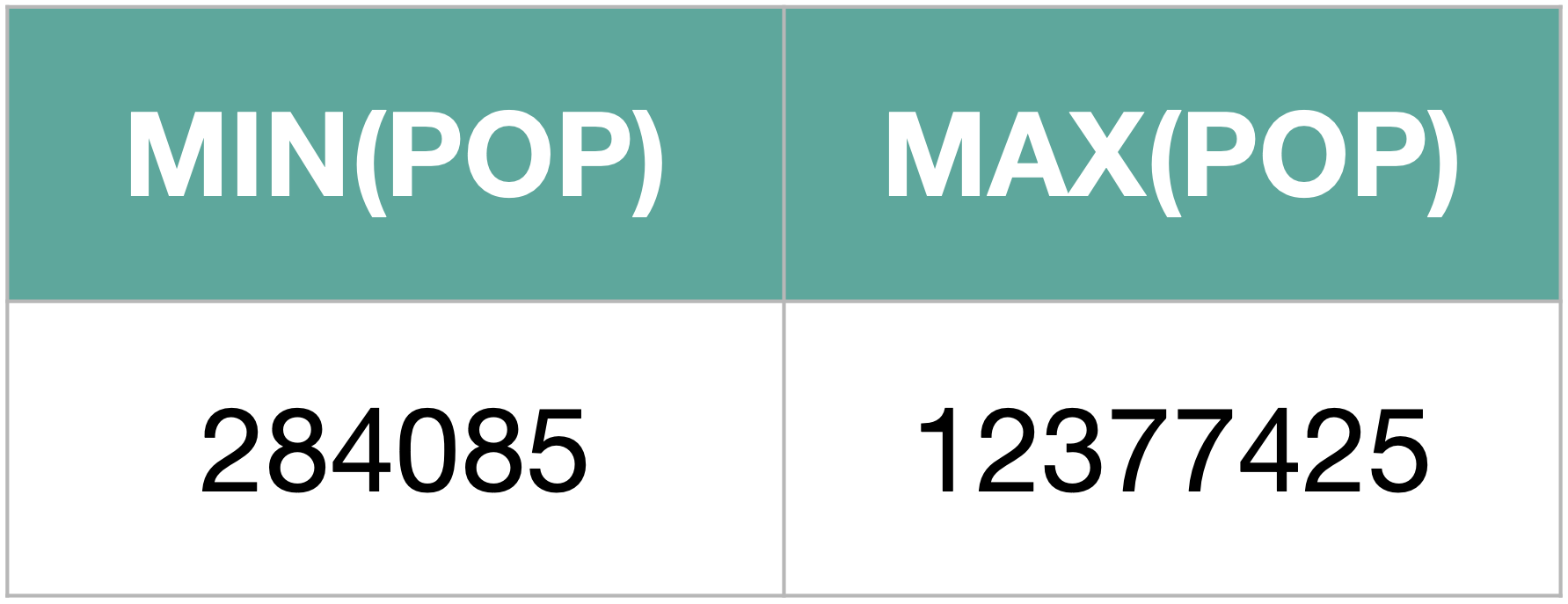
GROUP BY
Grâce à la clause GROUP BY, on peut grouper ensemble (partitionner) des lignes qui ont les mêmes valeurs dans une ou plusieurs colonne.
Mais c’est l’application d’une fonction sur chaque agregat obtenu qui en fait tout son intérêt.
Syntaxe générale d’une agrégation :
SELECTliste ordonnée d’attributs de partionnement, liste d’application de fonctions sur d’autres attributs
FROMliste de tables
WHEREcondition qui filtre les tables
GROUP BYliste ordonnée d’attributs de partitionnement
HAVINGcondition qui filtre les agrégats
Montrons comment on peut retrouver les attributs NBCOM et POP de la table Departements directement à partir de la table Communes :
SELECT CODDEP, COUNT(*) AS NBCOM_DEP, SUM(POP) AS POP_DEP
FROM Communes
GROUP BY CODDEP;
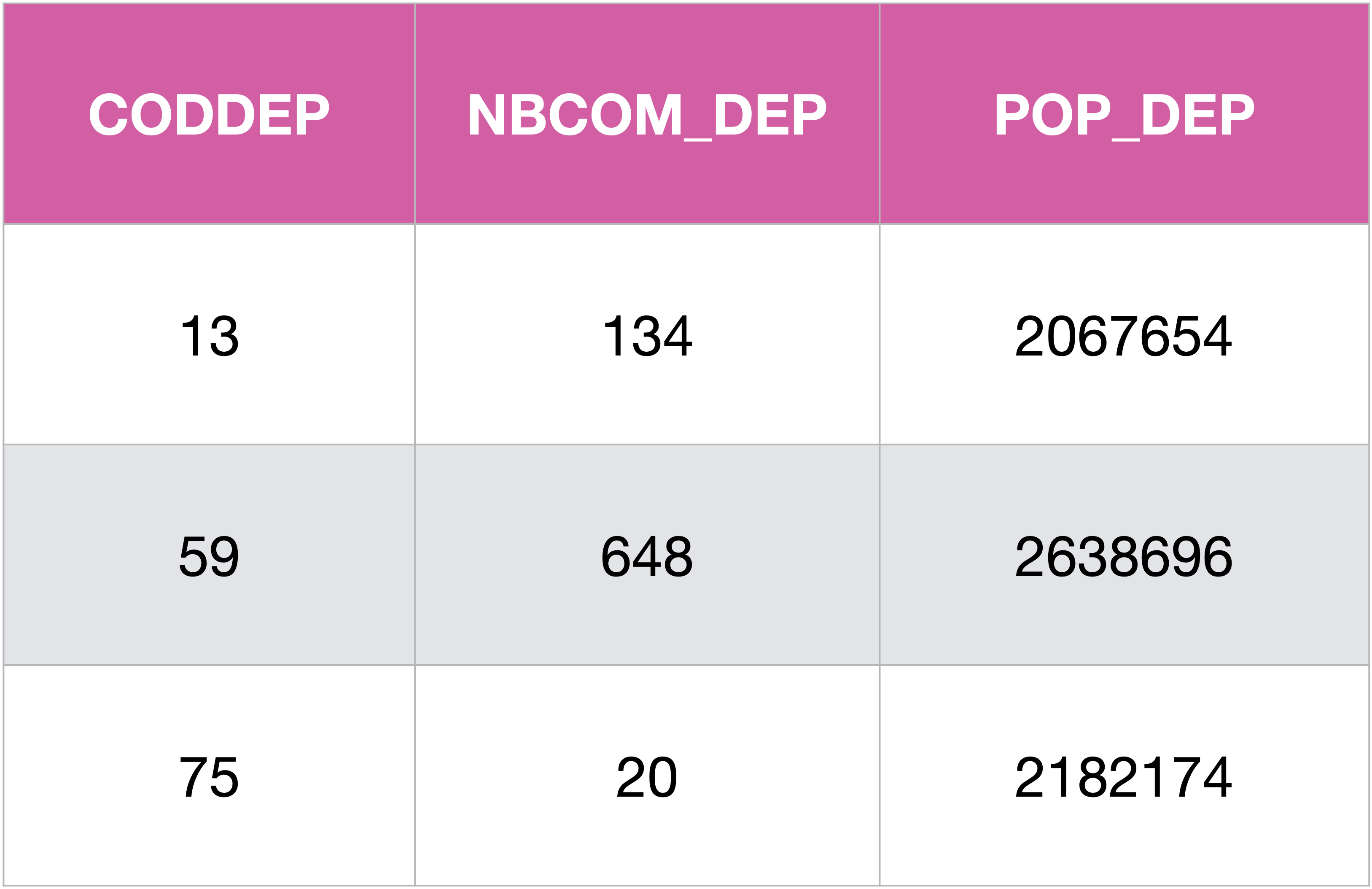
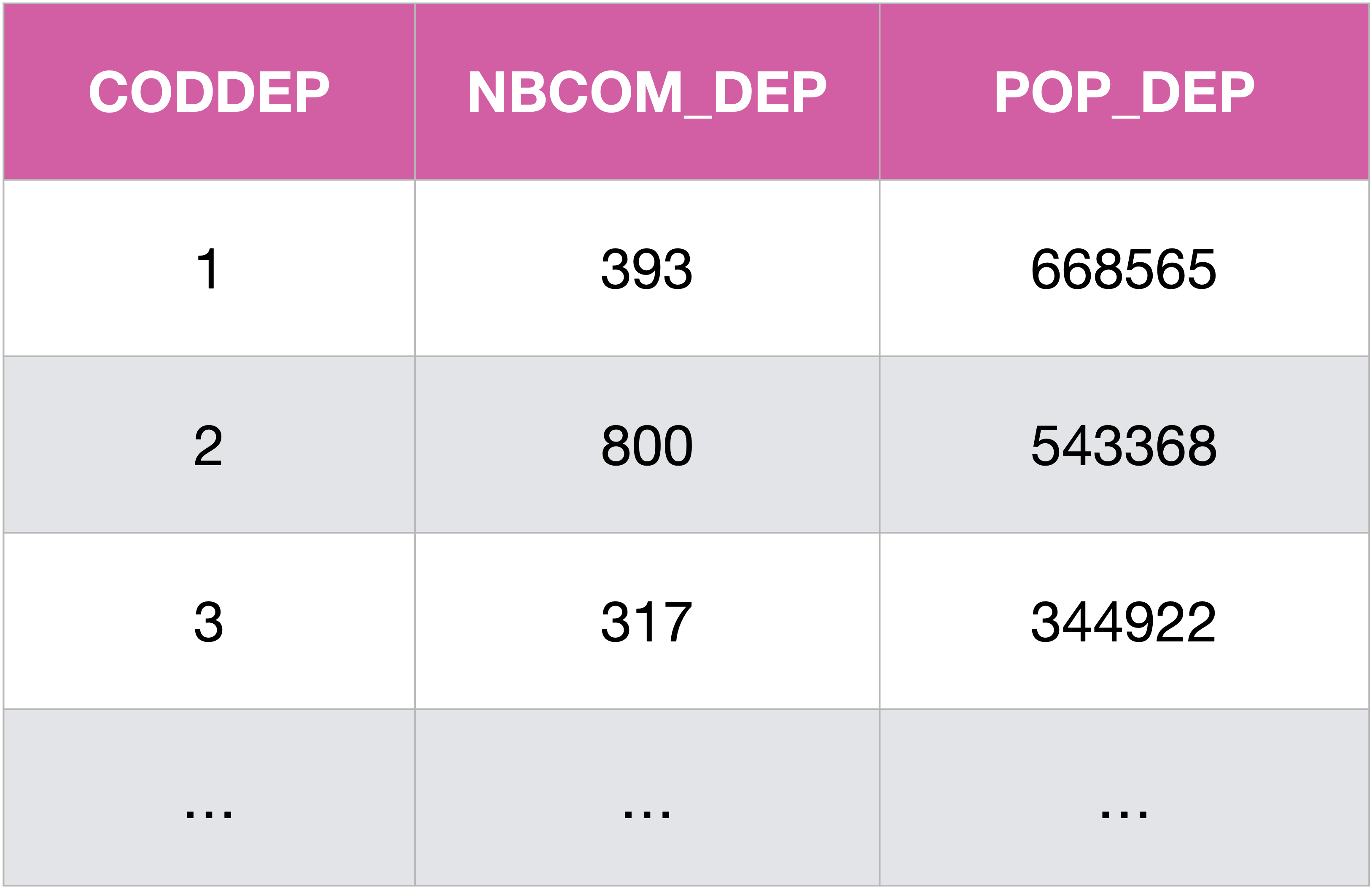 On retrouve bien les mêmes valeurs que dans la table
On retrouve bien les mêmes valeurs que dans la table Departements.
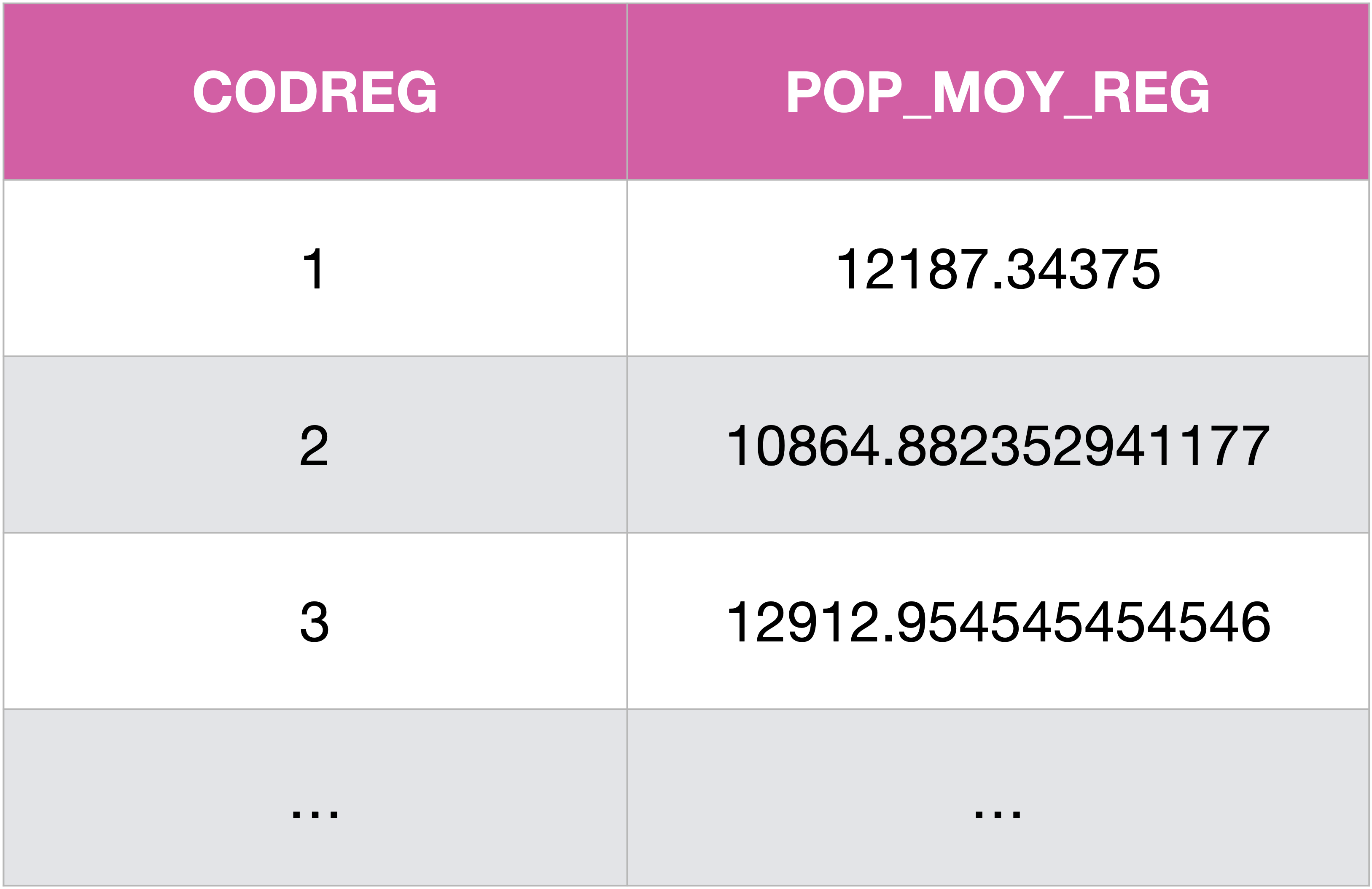
Supposons maintenant que l’on veuille connaître la population moyenne par commune dans chacune des régions :
SELECT CODREG, AVG(POP) AS POP_MOY_REG
FROM Communes
GROUP BY CODREG;
La clause HAVING permet d’effectuer une restriction sur les résultats de l’agrégation grâce à une condition.
Reprenons l’exemple des populations par département, mais n’affichons plus que les départements ayant une population supérieure à deux million d’habitant.
SELECT CODDEP, COUNT(*) AS NBCOM_DEP, SUM(POP) AS POP_DEP
FROM Communes
GROUP BY CODDEP
HAVING SUM(POP) > 2000000;
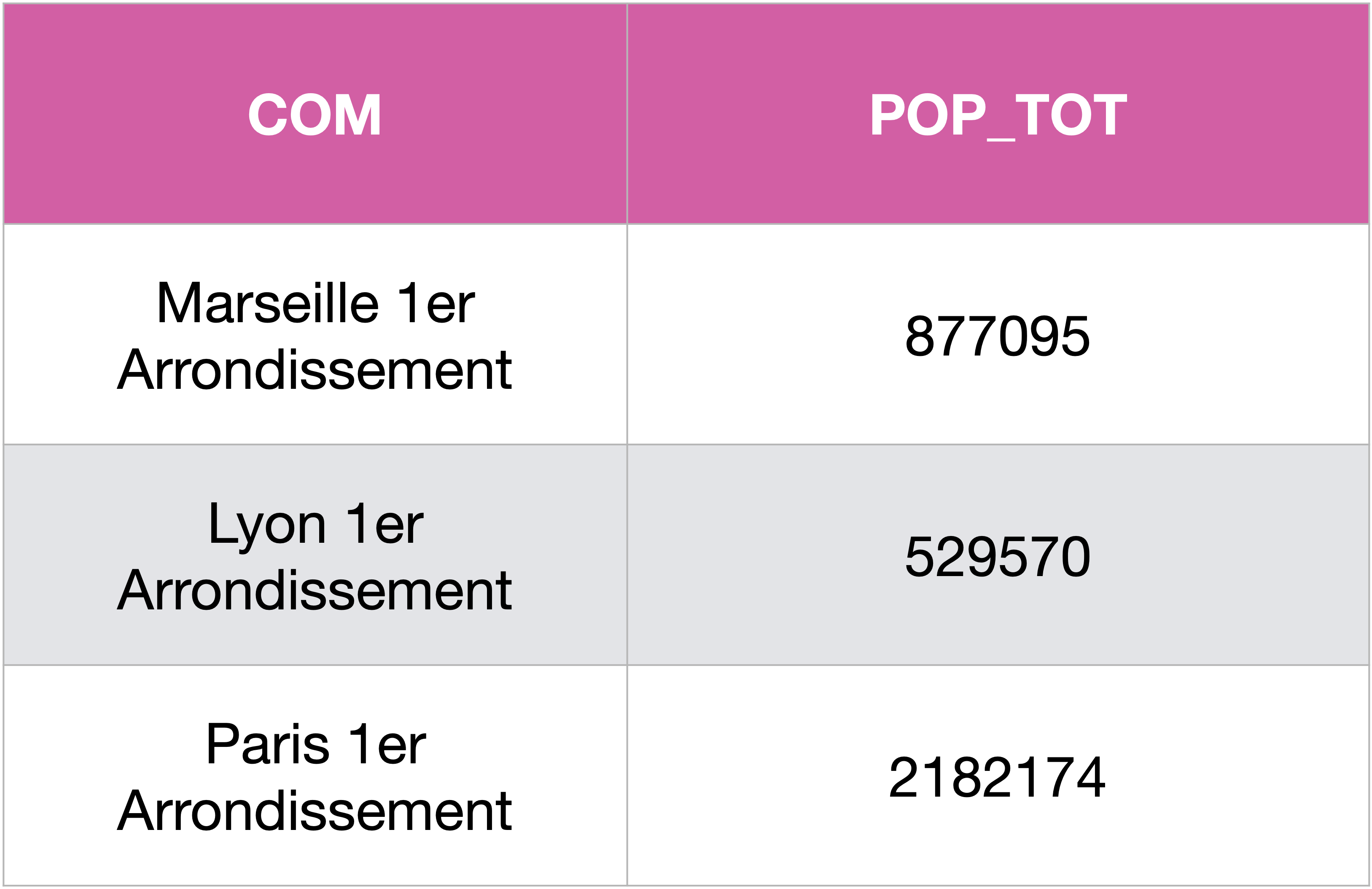
On a vu lors des exemples de tri que Paris, Marseille et Lyon n’apparaissent pas parmi les communes les plus peuplées, ce qui s’explique par le fait que chacune de ces villes sont découpées administrativement en arrondissements.
Essayons maintenant de regrouper ces arrondissements :
SELECT COM, SUM(POP) AS POP_TOT
FROM Communes
WHERE COM like '%Arrondissement'
GROUP BY CODDEP;
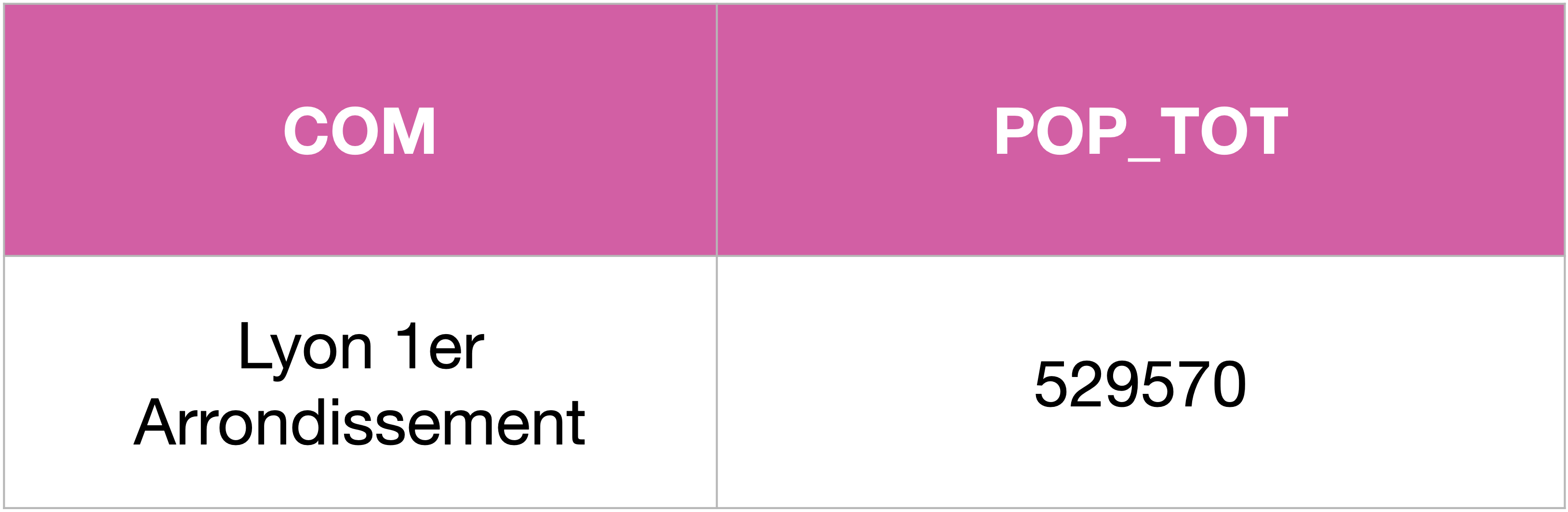
Et si on voulait opérer une sélection supplémentaire sur cet aggrégat de 3 villes, c’est un HAVING que l’on utiliserait. Par exemple :
SELECT COM, SUM(POP) AS POP_TOT
FROM Communes
WHERE COM like '%Arrondissement'
GROUP BY CODDEP
HAVING COM like 'Lyon%'
WHERE est un filtre sur les données ⇒ il s’applique avant l’agrégation par GROUP BY.
HAVING est un filtre sur les résultats d’un regroupement ⇒ il s’applique après l’agrégation par GROUP BY.
Opérateurs ensemblistes
On peut utiliser les opérations ensemblistes vues plus haut grâce aux opérateurs SQL suivants :
| Opérateur SQL | Opération |
|---|---|
UNION |
union |
INTERSECT |
intersection |
EXCEPT/MINUS |
différence |
La requête suivante donne les noms de communes qui sont aussi des noms de départements :
SELECT COM
FROM Communes
INTERSECT
SELECT DEP
FROM Departements;

Requêtes imbriquées
On peut enchasser des requêtes les unes dans les autres en utilisant des parenthèses.
Cette requête affiche le département ayant les communes les plus faiblement peuplées en moyenne.
SELECT DEP
FROM Departements
WHERE CODDEP = (SELECT CODDEP
FROM (SELECT *,AVG(POP) AS Moy
FROM Communes
GROUP BY CODDEP)
WHERE Moy = (SELECT Min(Moy)
FROM (SELECT *,AVG(POP) AS Moy
FROM Communes
GROUP BY CODDEP)))

Pour traduire de telles requêtes enchassées les unes dans les autres, le plus simple est de partir de la dernière et remonter.
Essayons maintenant d’intégrer nos villes à arrondissements dans le classement général des 10 communes les plus peuplées :
SELECT COM,POP
FROM (SELECT *
FROM Communes
WHERE COM NOT like '%Arrondissement'
UNION
SELECT CODREG,CODDEP,CODCOM,COM,SUM(POP)
FROM Communes
WHERE COM like '%Arrondissement'
GROUP BY CODDEP)
ORDER BY POP DESC
LIMIT 10;
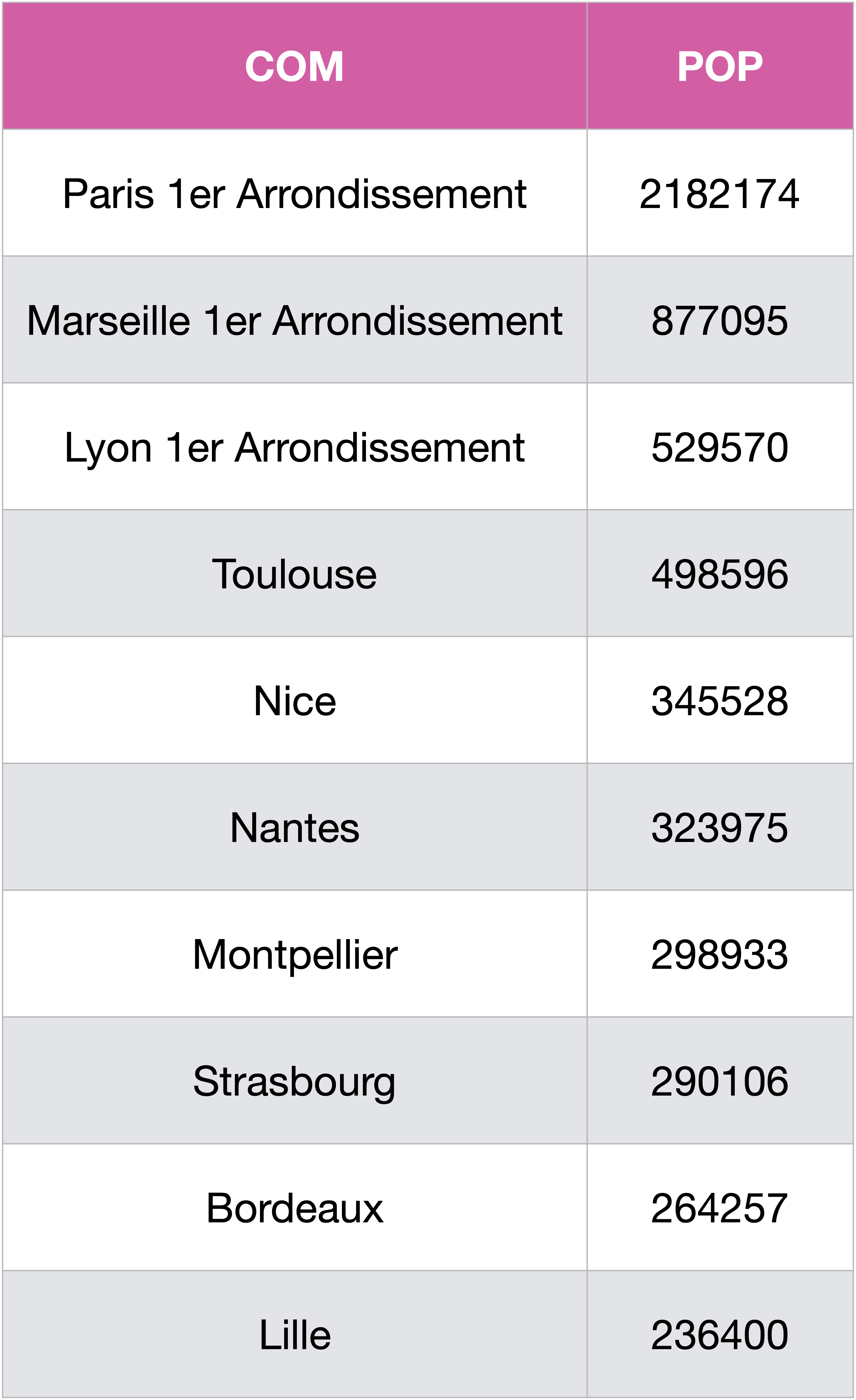
Pour que les 3 premiers résultats aient des noms corrects, on peut utiliser une commande CASE comme ci-dessous. Ce n’est pas au programme.
SELECT
(CASE
WHEN COM LIKE 'Paris%' THEN 'Paris'
WHEN COM LIKE 'Marseille%' THEN 'Marseille'
WHEN COM LIKE 'Lyon%' THEN 'Lyon'
ELSE COM
END) AS COM, POP
FROM (SELECT COM,POP
FROM (SELECT *
FROM Communes
WHERE COM NOT like '%Arrondissement'
UNION
SELECT CODREG,CODDEP,CODCOM,COM,SUM(POP)
FROM Communes
WHERE COM like '%Arrondissement'
GROUP BY CODDEP)
ORDER BY POP DESC
LIMIT 10);
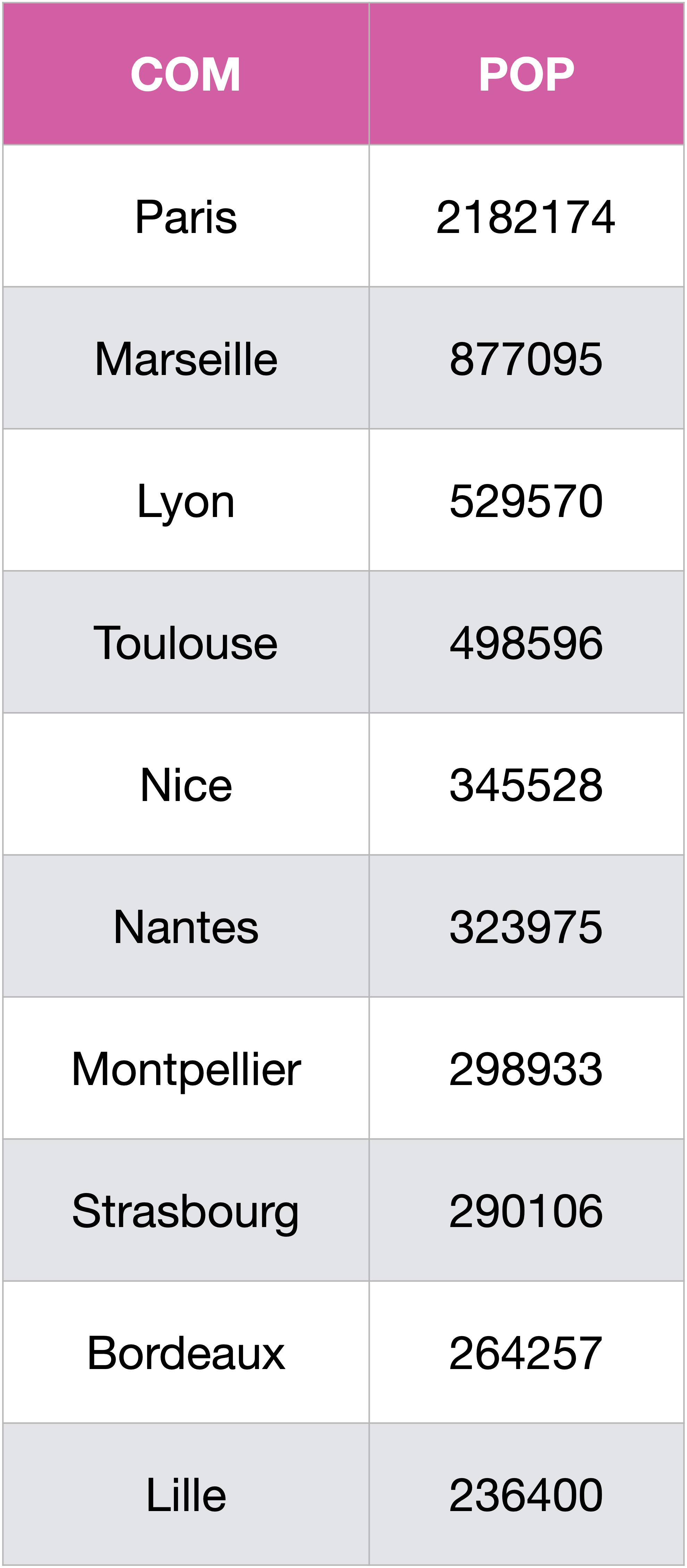
Jointures
Joindre deux tables peut s’avérer très utile et s’opère grâce à la commande table1 JOIN table2 ON condition.
Après le mot clef ON, on précise le critère de jointure. S’il s’agit d’un critère d’égalité (du type colonneX.table1 = colonneY.table2, alors on parle d’équi-jointure.
Les jointures évoquées ici sont des jointures internes. Ce sont de loin les plus utilisées et le programme de CPGE se limite à elles. De même le programme n’évoque que les équi-jointures.
On a obtenu plus haut un ensemble de communes dont le nom est aussi un nom de département. Associons-leur le nom du département où elles se trouvent grâce à une jointure :
SELECT DEP, Communes.COM
FROM Communes
JOIN (SELECT COM
FROM Communes
INTERSECT
SELECT DEP
FROM Departements) AS Inter
ON Inter.COM = Communes.COM
JOIN Departements ON Communes.CODDEP = Departements.CODDEP;
La première jointure sert à simplifier la table Communes de manière à ce qu’elle ne contienne plus que les communes ayant des noms de départements.
Et la deuxième jointure sert à associer le nom du département où elle se trouve à chacune de ces communes.
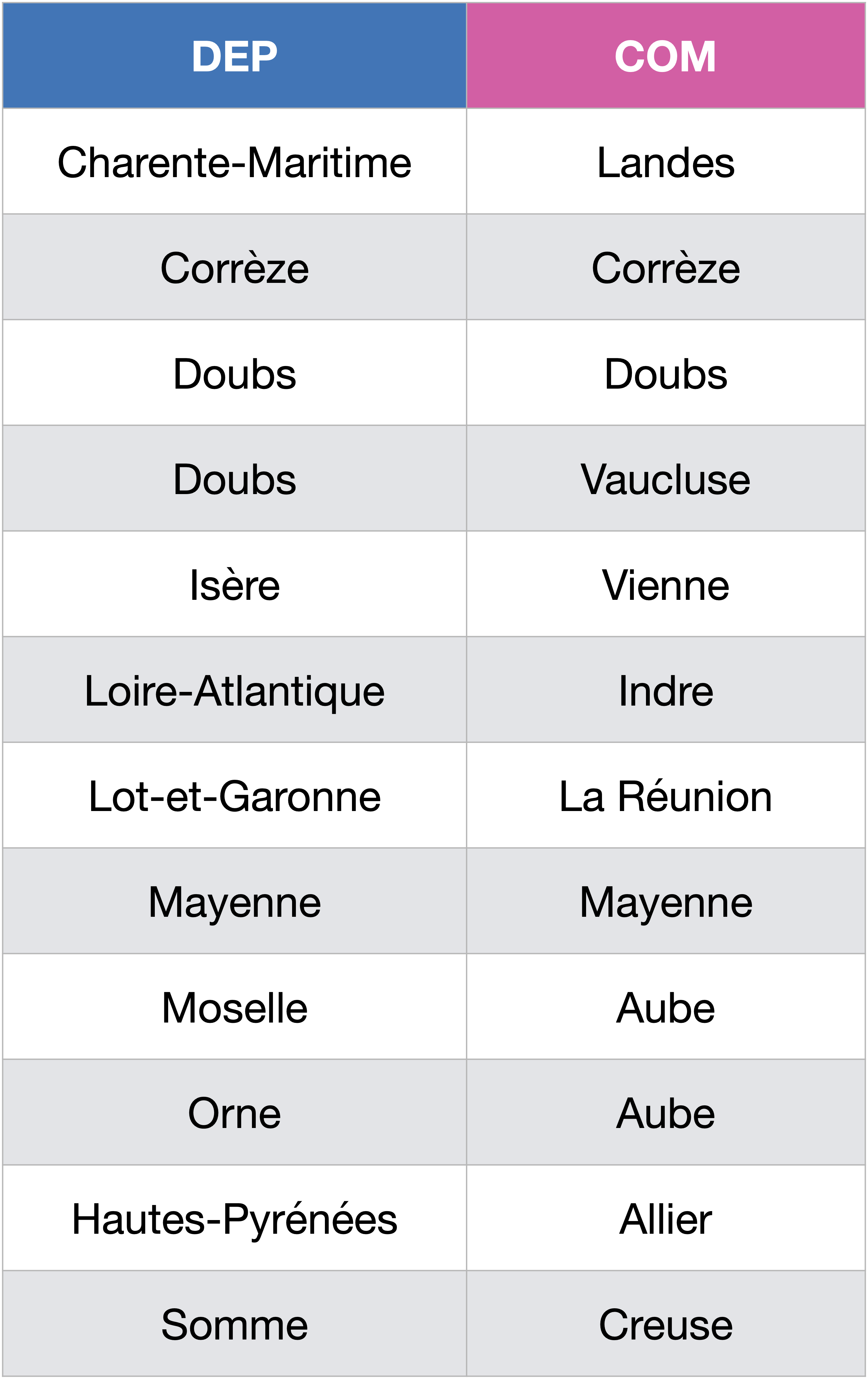
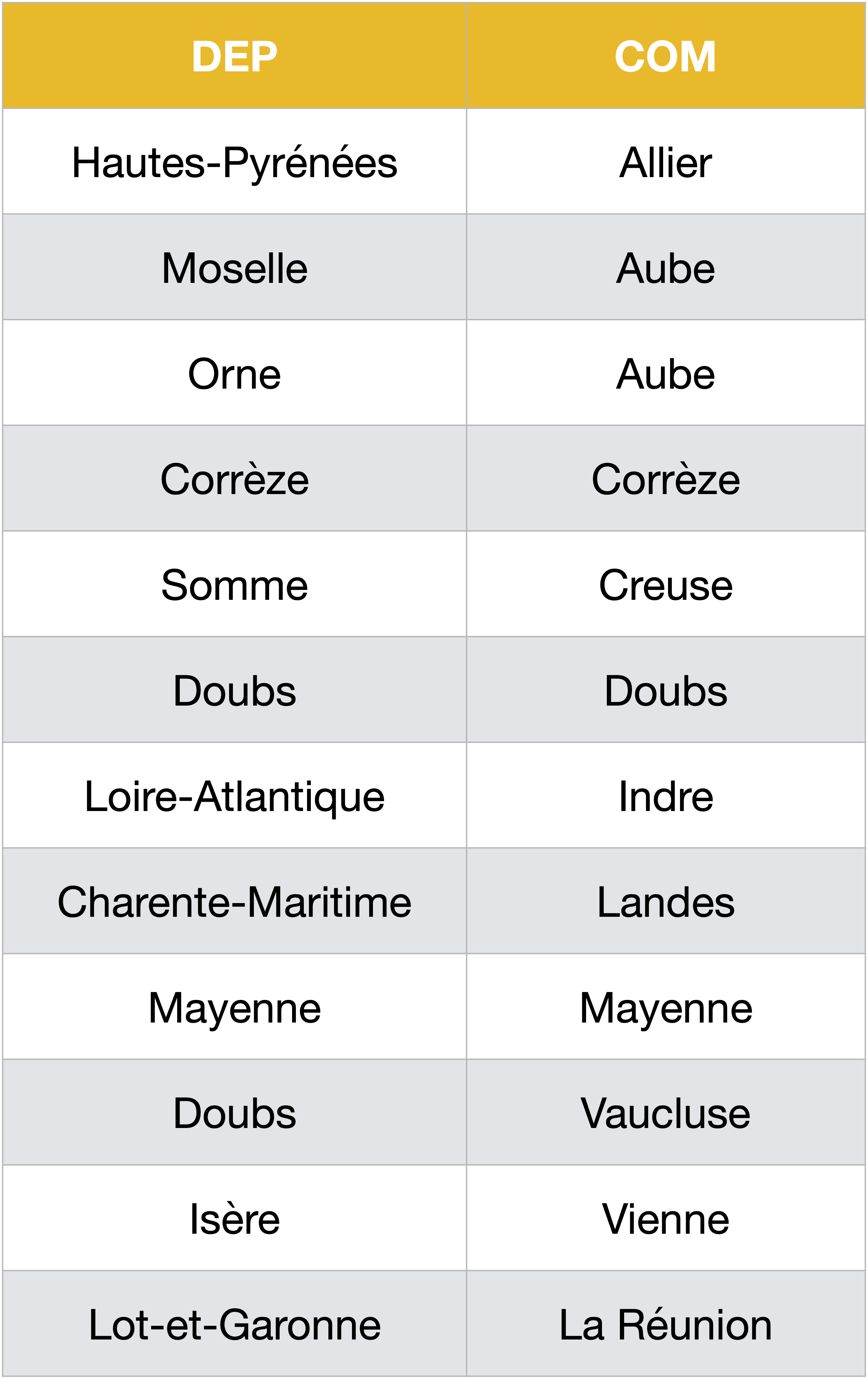
On constate ainsi que le Doubs, la Corrèze et la Mayenne ont une structure récursive…
On aurait pu obtenir le même résultat en joignant d’abord les tables Communeset Departements, puis en réalisant une auto-jointure sur le résultat de cette première jointure.
Une auto-jointure consiste à associer ensemble deux colonnes de la même table. Cela nécessite d’utiliser deux alias différents pour désigner la table, sinon le moteur SQL est tout perdu (erreur ambiguous columnn name)…
SELECT DISTINCT DEP, COM
FROM (SELECT * FROM Communes
JOIN Departements
ON Communes.CODDEP = Departements.CODDEP) AS ComDep1
JOIN (SELECT * FROM Communes
JOIN Departements
ON Communes.CODDEP = Departements.CODDEP) AS ComDep2
ON ComDep1.COM = ComDep2.DEP;